Wednesday, September 23, 2009
评论:框营销才是百度的终极目标
 http://www.cnbeta.com/articles/94131.htm
http://www.cnbeta.com/articles/94131.htm
感谢XJP的投递

21号,我在“百度框计算不过东施效颦而已”一文里面讨论框计算的时候,有提到百度很可能通过所谓的框计算来牟利,实现竞价排名与框计算营销的高中低端全面覆盖。
框计算能够实现更多的互动操作,并且展示形式更加多样化,所以这样的服务是针对高端客户。门槛高、资金消耗大,适合B2C、机票、销售等类型网站 投放。相比传统的竞价排名无论在展示形式还是转化率都占据更大的优势,能够有效填补百度推广产品的空白。下面就来讨论百度可能出现的框计算营销。
首先百度的框计算本质上是服务商提供一个应用接口,让用户可以直接在搜索结果页面实现需要的操作,例如机票酒店查询和预订、网络购物、点卡充值 等,从技术层面来讲完全可以通过Ajxa实现一页式服务,即用户可以在百度的搜索页直接实现查询、预订、付款等操作,付款这一步也可以捆绑百度自己的百付 宝,这是一种巨大的突破,至少方便了用户。
但是一旦涉及到利益就会出现利益分配的问题,继续前文的假设,如果百度与艺龙达成合作,百度将会在机票、酒店相关关键词将艺龙给框进去,没准还真 能够颠覆目前的市场格局,毕竟大部分用户喜欢简单,能够在搜索页完成一切操作绝对是一种体验上的创新。这就是百度框计算营销的可怕之处,按照这种逻辑,任 何市场它都可以利用自己的垄断地位强插一脚,直接从成交分成。
例如:百度在把旗下有啊给框进去,有啊估计能够直追淘宝、拍拍;百度要求所有加入框计算的应用必须使用百度宝支付,在线支付可能会面临两强相争的 局面;百度把慧聪给框进去,阿里巴巴市场份额将会被挤压;百度把京东给框进去了,新蛋估计就难受了;以后百度一搜索邮箱第一位就显示百度邮箱(尚未推出) 的注册和登陆链接,估计邮箱巨头网易也会抖上一抖……
你是不是已经被这些假设给震惊了,是的,几乎可以肯定的是百度的框计算营销将会继续向这个方向发展,赚钱和搜索两不误。背后凸显的现象是搜索引擎 已经成为大多数用户上网的入口,一个很典型的案例是很多用户是打开搜狗搜索的是百度,然后在百度里面搜索谷歌,然后去谷歌资讯看财经新闻。早起的鸟儿有虫 吃,既然百度的框计算营销已经是无可避免,那么大家不妨未雨绸缪,谋划一下自己是否需要框一下。
结论就是我们都给百度骗了,所谓框计算,框的就是你。
原文:http://www.xjp.cc/2009/09/23/baidu-box-marketing/
Labels: Baidu, search engine
Friday, August 22, 2008
搜索RapidShare资源的几种方法
rapidshare 改版了,上面有很多keygen之类的资源下载。好吧,就谈谈如何搜索rapidshare上面的资源吧。说rapidshare是一个大金矿一点也不 错,作为世界上最大的在线存储服务器商,每天有非常多的人上传东西,尤其是里面还有很多特别的东西。但是rapidshare本身不提供搜索功能,这的确 是一个遗憾。
那么如何搜索rapidshare资源呢?
首先当然是利用搜索引擎啦,大多数搜索引擎都提供了高级搜索参数,利用这些,你可以轻松搜索rapidshare.com甚至别的同类网站。
比如google,你可以搜索“keygen site:rapidshare.com”这个关键词,列出来的都是各种各样的keygen:

太多了吧,那就再详细一点,例如搜索“microsoft keygen site:rapidshare.com”。看到了你想要的吧,呵呵:)

现在把“microsoft”换成你想要的关键词试试看吧!
除了使用google这种通用搜索引擎之外,还有很多专用的rapidshare搜索引擎,下面我选了几个我认为不错的。
1.Rapidshare1.com
名字非常好记的一个搜索引擎,只需要在rapidshare后面加个1就可以了。
rapidshare1.com的界面非常不错,看上去非常舒服。支持添加到IE和Firefox的搜索引擎列表,这样就可以在搜索引擎直接调用了。如果你是站长,还提供了一段PHP代码,让你的网站也拥有这一功能!

我觉得rapidshare1.com最大的缺点就是广告太多,还是弹窗广告呢,一不小心就跳了很多广告出来,很烦!
还有一个Rapidshare-searcher.com和这个rapidshare1长得十分相像,难道是李逵和李鬼?
2.RapidLibrary.com

RapidLibrary的一个特点就是允许用户自行提交文件,使得来源不再单一是google等搜索引擎了。
这个号称最大的rapidshare资源搜索网站的功能很丰富,能按照文件类型来搜索。出来的结果除了标明大小和能够自定义排序外,还能判断出文件是否已经被删除,非常不错!

当你访问搜索出来的链接时会要你安装一个Zango的软件,这个东西被我的NOD32报Adware.180Solutions广告程序,但如果不安装这个似乎又没办法得到地址,请大家自己决定吧。
RapidLibrary旗下还有一个4MegaUpload.com专门搜索megaupload上的资源,可以看看。
3.Rapidshare-search-engine.com
R-S-E同样是一个著名的rapidshare搜索引擎,而且同时支持rapidshare.com和rapidshare.de这两个网站。

同样支持提交文件,可选择使用web搜索或网站自己的数据库搜索。
支持ajax效果,上图中的那个那个“圆形的齿轮”搜索时会转动,很好玩……
R-S-E还提供了一个Firefox扩展,有获取本页rapidshare链接和测试获取的链接等功能,用FF的朋友可以试一下。
不过网站很不稳定,我已经遇到了几次的错误,严重影响体验啊!
另外再推荐Funfail和rapidshare.tvphp.net这两个,前者支持RapidShare、MegaUpload、TurboUpload和SendSpace等网站,后者支持按照文件类型搜索,都很不错!
除了上面说的,你还可以使用google的自定义搜索来创建一个属于你的rapidshare搜索引擎,方法网上很多,自己找找吧!
Labels: RapidShare, search engine
Friday, December 14, 2007
人工搜索Mahalo.com研究
--James Qi(讨论) 2007年10月25日 (四) 15:29
为了准备我们未来的关键词搜索Wiki想法,最近找了一些相关搜索网站来研究,我会陆续把研究记录放在日志中。
先来看看人工搜索的新贵Mahalo.com,这是我目前在网上找到与我们的想法最接近的项目。
简介
Mahalo是夏威夷语“谢谢你”的意思(Wiki也是夏威夷语,现在网络上世道真是变了,夏威夷语这么流行 ![]() )。
)。
它是由业内知名的搜索引擎专家Jason Calacanis创建,此人把以前创办的Weblogs Inc以2500万美元的价格出售给AOL,这次在2007年5月30日推出了号称第一人工搜索引擎的Mahalo,引起VC界的关注,刚开始就获得不少 投资。在网上搜索到的一些中文介绍都是6月初发布的,我到10月才开始关注、看到,真是落伍了!![]()

下面摘录一点报道中的内容:
Mahalo 是世界上第一个台人肉搜索引擎,他们由一些热心人提供动力,这些人废寝忘食地将自己的青春花费在搜索上面,帮你过滤掉垃圾信息,手工编辑最佳的搜索结果,而且如果没有你需要的结果,还可以向他们提交搜索申请 ……
Mahalo 不收录的网页:
- 垃圾邮件网站;
- 非垃圾邮件站点但包含欺诈性广告的站点;
- 恶意获取个人信息的站点;
- 只会复制重不原创的站点;
- 非法复制内容(没获得许可)的站点;
- 火星人建立的站点;
- 成人内容或者令人恶心的内容的站点。
Mahalo 收录的网页:
- 在某个领域权威的站点;
- 高品质原创内容的站点;
- 运作一年以上的站点;
- 涉及清爽,广告在可以忍受的范围之内的站点。
上面是他们自己介绍的,虽然翻译得不好,但它其实是一个严肃的项目,创建人是搜索领域赫赫有名的 Jason Calacanis。这一项目的原动力在于,虽然搜索词是不可限定的,但事实上有一万个搜索词占据了所有搜索 24% 的份额,人工编选的结果和机器搜索其实是很容易很出来的,而那 76% 的“长尾”,就留给 Google 好了。
CNET 对它的评介是,搜索结果匹配度非常地高。

平台
打开他们网站 http://www.mahalo.com 看看,因为我成天接触Wiki用的MediaWiki软件,所以马上就发现该网站所用平台与MediaWiki惊人相识,同样有Category、 History等,今天上午再仔细看看,确实就是用的在开放源代码软件MediaWiki基础上修改过的系统做为平台(这点上与WikiHow相同),不过他们修改的幅度比较大,主要是适应他们的一些特点,例如不允许浏览用户编辑但可以推荐和讨论,也增加了很多插件来实现他们需要的功能和界面。
页面打开特别快,不像其它一些国外的英文网站打开很慢。我故意打错一个链接,看到Squid出错的提示,看来也是用了与MediaWiki配合做缓存的Squid服务器。
使用MediaWiki平台来做各种网站项目确实是个好的办法,上面的两个例子网站都是很知名的了,我们自己现在也是这样做,但我们现在还没有找人来进行针对性开发,以后是需要的。
内容
该项目目前是全英文的。
首页上有一个搜索框,然后下面是分类及热点文章。
5月30日推出的时候有4000个关键词,当时说到今年年底准备做10000个关键词。
我在页面底部看到“Mahalo's goal is to hand-write the top 20,000 search terms. ”,也就是他们准备做20000个搜索量最大的关键词出来。
从已经做好的文章内容来看,质量是没有话说的,远比通用搜索引擎(例如Google, Yahoo!等)给出的结果好,到底是人脑厉害!![]()
页面
进入一个典型的关键词Paris Hotels页面后,看到:

上方
包括:
- 返回首页链接
- 搜索框
- 分类
左侧
包括:
- 标题
- 相关文章(See Also, Do You Mean)
- 推荐Top 7网站
- 其它标题(例如与关键词相关的新闻、视频、历史等)及推荐网站
- 相关搜索(指向更多的相关内部文章)
右侧
包括:
- LOGO
- 编辑笔记
- 快速内容
- 最多推荐链接
- 分享本页
- 今日热门页面Top 10
- 图标含义(Warnings / Guide's Choice / What is?)
下方
包括:
- 作者名称及链接
- 浏览者推荐链接
- 最近更新时间、查看历史链接
- 搜索框
- 分类
- 到博客和Greenhouse(参加编辑的项目组织网站)的链接
- 使用说明、隐私政策
组织
他们招聘有40位专职的编辑人员,另外通过 Greenhouse 招收业余兼职编辑,每篇符合要求的文章付费10-15美元。对编辑人员进行分级别。
按照他们自己的说法,写一篇文章一般需要几个小时。然后还有定期的后续维护。
给编辑人员的帮助我重点看了看,包括编辑内容的质量要求、格式的编排、准备的模板等,准备得还是很充分的。
其它
其它的一些了解到内容:
- 无结果页面:对于还没有编写内容的关键词,系统会给出相关文章列表和Google搜索结果
- 收益:以后靠广告收入,目前专注于高质量内容的建设,另外通过Google搜索结果中的广告可以分享收入
Labels: search engine, SNS
人工搜索Chacha.com研究
--James Qi(讨论) 2007年10月29日 (一) 15:33 (CST)
在Google中查找“人工搜索”,除了Mahalo.com以外,还有一个Chacha.com,其结果比Mahalo.com更多、更靠前,于是我也去看看,并做如下记录。

很不幸,前几天第一次打开http://www.chacha.com 的时候竟然遇到"Maintenance"的提示,让人怀疑其技术能力和服务水平。![]() 今天打开倒还算顺利,看到图标。
今天打开倒还算顺利,看到图标。
从页面上看,这是一个英文的搜索引擎,只是除了普通的Search按钮以外,还有一个Search with Guide的按钮,据说这就是向人工向导求助。因为时间的原因,我就没有尝试向人工求助,据国内用过者评价体验还不错。我只试用了普通Search,感觉 与Google也没什么两样,只是排列有些不同,广告比较多。尝试查找中文内容出来了一些乱码,但找到的网站还是对的,应该是显示编码方式的问题。
从About中看到Chacha.com和Mahalo.com一样有着明星Founder兼CEO:Scott Jones, CEO & Co-Founder和Brad Bostic, President & Co-Founder。两者还有点相似,名称都来自外文谐音,Chacha还真是来自中文“查查”![]()

为了看清其流量,依然从Alexa排行来观察。从Alexa排名对比来看,去年起步的Chacha比今年起步的Mahalo落后很多。
Chacha.com与Mahalo.com都有人工参与,但很大不同之处是Chacha.com让人工来实时与用户联系,有针对性地 帮助用户找到合适内容,而Mahalo.com却是让人工在后台埋头编写热点关键词的页面,用户可以找到这些高质量的内容做为参考。从用户的角度来说 Chacha似乎更有帮助,但效率肯定是低下的,在美国人工费用也是昂贵的,我估计网站上的那点广告收入肯定是不够支付人工报酬的。这有些类似目前我们做Wiki网站群的情况,而且越向后期发展会感觉越明显。明星自己的腰包和VC的投资总有用完的时候,看不到流量和收入前景就难以继续的!
综合以上的情况,我更看好Mahalo.com的前景,而Chacha.com有些危险,在经历了推出的风光后,现在应该是艰难的时候,让我们大家继续看看他们以后的发展吧。
另外几个相关搜索网站看了看,一并简单记录:
- Wikiseek.com:已经推出,专门搜索Wikipedia内容的搜索引擎,得到维基百科官方认可和支持,收入大部分捐献给维基百科,但目前看Alexa排名20多万位以后,每天没有多少人用;
- Wikiasari:维基百科创始人Jimmy Wales创建Wikia后准备继续做的人工搜索,据说要挑战Google,但推出时间一再延后,现在还看不到任何东西,但人们还是很期待到底会出来什么内容;
- DMOZ:全球最大、最老的人工分类目录,早些年对一个网站来说非常重要的是被DMOZ收录,但近一些年更新太慢,组织不力,日现老态,已经不再重要;
- Ask:看上去就是一个普通搜索引擎,比较一般,流量却很高,Alexa排名目前215位,看了几篇说其与Google不同点的文章,但还是认为没有特别突出的地方;
- Answers:搜索结果属于整合信息,包括维基百科的内容、大英百科的内容、可能关联的商品、天气等等信息,我还比较喜欢,其整合应该都是机器整合的,没有听说人工参与。
Labels: search engine, SNS
Tuesday, September 25, 2007
李开复:以人为先定义Google未来搜索战略
2007年互联网大会进入第二天,在上午的“网络领袖创新论坛”上,Google全球副总裁兼大中华区总裁李开复发表演讲时表示,未来搜索将会进入一个以 人为先的时代,以人为先有四个定义:
整合搜索,移动搜索,智能搜索和个性化搜索.
李开复透露,这四个搜索听起来都是非常长远,非常高科技的,其实这四个题 目都已经融入谷歌的产品里面了.
李开复表示,在过去当你进谷歌,或者任何一个搜索引擎,你下一个搜索词的时候,你所搜索的东西是一个所有的网页的索引,它会在网页基于文字的匹配给你一个回答,但是慢慢地我们发现了网页的文字搜索是不够的.Google把各种数据库统统结合起来,在用户体验方面,只要一个搜索框,在后排的数据库索引方面我们只要一个数据库,它可以把所有垂直搜索都搜取过来,然后把各种多元的信息,无论是图片、资讯、视频,还是商品,或者是餐馆信息,都能把它整合起来,所以这叫做整合搜索,就是一个搜索框,所有多元的结果被整合起来.
第二个方向是移动搜索,我们都知道中国的移动用户已经超过了PC用户,我们也相信将带在这样一个3G时代来临之后,在移动上会有非常多的应用,很多人说移动搜索很困难,因为屏幕很小,但相对来说移动搜索也有很多好处.除此之外,我们还想把整合搜索推到移动手机上,包括图片的搜索,也还有相关的搜索,在手上像PC一样能够获取,我们深深的相信在手机上和在PC上一样丰富多元的信息, 给用户提供一个非常好的体验.
第三个方向是希望未来在整合搜索基础上发展出一个智能搜索,智能搜索非常聪明,不是永远给你静态的结果,而是能够分析不同的情况之下给你最合适的结果,不同的情况包括时间、地点和语言.当你搜索地震的时候,12月底搜,可能看到的是台海地震,到 1月19号搜索地震,结果是东京,还有第一次地震造成海底光缆的影响,它会因为时间同样一个搜索词给你不同的结果.李开复透露,在谷歌.CN跟谷歌.UP 搜出来的结果,也会智能地做排序,它会针对你在什么地方,会有什么兴趣,而进行排序.
第四个方向是个性化搜索,对每一个用户提供对这个人最有针对性、最有利的搜索结果呢?个性化搜索就是要做信息挖掘,要知道每一类人的搜索习惯.比如我刚搜索了联想,我再搜索苹果,这个苹果可能指的就是苹果电脑,它会根据人的搜索习惯来判断.比如我知道这个人属于汽车爱好者,如果我知道他拥有一台QQ,这个时候我就会把奇瑞QQ排在前面,这些都是根据个人的习惯,还有他所属于的社区等等,来做更好的判断.
Labels: search engine
Friday, August 31, 2007
个性化搜索工具大比拼
从“My Search History”我们可以看出,Google为实用性和易用性制订了一个新标准。其实早在去年,Ask Jeeves和雅虎就分别推出了自己的个性化工具,AOL搜索也在近期更新中增加了一项搜索历史的特性。但这些工具都无法和Google的这款“My Search History”相媲美。
去年的9月份,Ask Jeeves推出了可存储历史搜索记录的“My Jeeves”个性化工具,被搜索引擎观察的主编Danny评价为:Ask Jeeves迈向个性化搜索的蹒跚学步期。Danny更表示:MSN早在1999年就通过IE浏览器提供过个人搜索历史的功能,但这款工具当时显得曲高和 寡。
雅虎的“My Yahoo! Search”个性化Web搜索服务测试版是在去年的十月份发布的。用户可以通过这项功能更好地搜索、管理并分享查询结果。虽然我被这款服务所深深吸引, 但最后我还是认为它没有足够的魅力吸引人们使用它。而且雅虎和Ask Jeeves提供的个性化搜索工具都是隐藏起来的,而且有其独立的接口,但Google提供的这一款“My Search History”则直接集成到Google的主页面及搜索结果页上。用户无须其它操作。既方便又省事。
其它搜索引擎提供的个性化搜索服务包括A9.com和Eurekster。象Looksmart提供的Furl、Onfolio、Nextaris等特色搜索工具也都不错,用户可以通过这些功能来创建自己的网页档案,并能够搜索这些信息。
但 上述这些搜索引擎提供的个性化搜索工具距离与一个主要的搜索引擎直接集成起来仍有一步之遥。虽然较之于其它公司推出的个性化搜索工具,Google的这款 “My Search History”无法囊括它们的所有特性,但迄今为止,它仍不失为主流搜索引擎所提供的最好的,同时也是最乐意为用户接受和使用的一款个性化搜索工具。
很久以来,个性化搜索就被一些人说成是搜索业的“圣杯”之一。无论是雅虎、Ask Jeeves、MSN还是AOL搜索,都一定会奋起直追的。使我们感到欣慰的是,今年,这些公司在寻求向用户提供实用性搜索结果和尊重和保护用户的个人隐 私这两者之间适当的平衡关系上达成了一致。随着Google的My Search History的发布,我寄望能够在个人搜索领域看到质的跨越。
“My Search History”目前能够支持的浏览器包括:Internet Explorer 4、Firefox、Netscape 6、Mozilla和Safari 1.2。
Labels: search engine
社会化搜索、个性化搜索
scoopgo: 个性化的搜索引擎,类似的还有Rollyo和Eurekster Swicki.
目前最主要的个性化搜索提供者包括Google的Personalized Web Search和Eurekster。
---Rollyo、Yahoo Search Builder、PSS!和Eurekster swickis
网络搜索是眼下的热门话题,大部分注意力都集中在Google和Yahoo这些搜索巨头上,而不是那些正尝试通过新技术来完善搜索服务的小公司。PubSub和 Rollyo 就具备一项Google和雅虎等主流搜索引擎不具备的特色。PubSub是一套自动系统,它不间断地在数以百万计的博客、在线讨论、新闻稿和美国证券交易委员会(SEC)存档文件中寻找和你的关键词匹配的内容。Rollyo的意思是“启动你自己的搜索引擎”。虽然它用的也是雅虎的搜索技术,但允许你把检索的网站限制在那些你相信能产生最佳效果的网址上,从而锁定你的查询。这种个性化设置的搜索引擎叫“searchroll” 。
---
Eurekster Swicki是一个免费的面向个人的搜索引擎服务网站,它提供的功能类似Google的AdSense for search,但总体感觉要比它更加强大。到这里可以试用一个我的搜索。
说起 Eurekster 可能知道的人不一定那么多,不过提到他们旗下的产品,一个社会化搜索引擎 Swicki,应该就有不少人知道了。最近他们完成了第二轮融资,领衔这一次投资的是第一轮投资的资方,来自于澳洲的 Technology Venture Partners 和来自于日本的 Transcosmos Investments,总额达 550 万美元。之前,已经有不少人拿 Swicki 与 Google 的搜索服务作比较,虽然目前看起来这样的比较炒作成分多于实际意义,不过给点时间和空间发展,最后的结果其实还尚未可知,包括像 ChaCha 等一类社会化搜索,作为传统网络搜索引擎到人工智能在搜索引擎上应用完成的一个过渡,社会化搜索引擎在未来几年会有一个不错的发展趋势。
Eurekster也是原始的Web2.0风格的网站之一,而且,经过一段时间的发展,Eurekster表现得越发成熟。Eurekster的主页做得相当好,声明了在线人数,以及产业新闻——从其社区进行Web搜索获得。我以前非常喜欢Eurekster,贡献了很多流量呢,因此,我知道人们为什么这么喜欢使用Eurekster。Eurekster的组织形式基本上是使用wiki 或者‘swicki’搜索,这使得搜索范围变小、目标明确,从而使搜索出的结果相关性非常高,更容易得到信息。能够搜索20,000条swickis记录,Eurekster似乎已经达到了增长的最高点,这是一个很好的开始。那么它会成为Google的障碍么?这很有可能,虽然它依赖Google,但是它异军突起,这也是为什么我会把它加到这个网站列表中的原因。
打开Eurekster(www.eurekster.com)之后,你 会问这是个搜索网站吗?搜索框在哪里?这个搜索网站跟我们平时所见的搜索网站真的很不一样呀。其实转动你聪明的大脑,小小研究两分钟,你就会搞明白是怎么 一回事了。原来这个网站最大的不同就是,要搜索,先要建立自己的Swicki或者使用已有的Swicki。那么这个Swicki又是个什么东东呢?简单地 说,它就是一个社区,它与Myspace 里的社区相似,但不同的是Swicki这......
EurekSter记录搜索引擎针对每个URL的点击,然后在相应URL被其他关键词搜索到的时候进行“相关关键词”提示。 这个机制我觉得很像Booso.com:
一 个基于搜索引擎referer的引擎:Booso是卢亮基于一个页面referer统计计数器引申的服务:计数器记录下了每个网页的所有REFERER, 其中来自搜索引擎的关键词就成为这个页面的主题词: 你可以查到你的网页被用户:在用什么搜索引擎和什么关键词搜索到的。
EurekSter的另外一个功能就是根据你朋友的偏好调整结果排序。
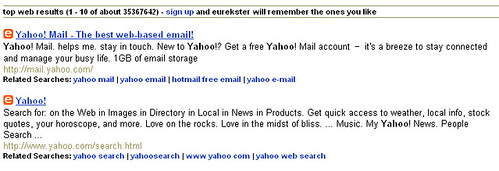
当Google这样的公司瓜分整个搜索市场,一些GEEK们自然会关心谁是第二梯队,谁是垂直领域的领先者等等......要提的名字很多如Quigo、IndustryBrains、Mooter、Eurekster和Dipsie等等一大堆熟悉或不熟悉的公司,但其中一个趋势是为用户提供个人化的搜索结果,当然,Google与雅虎也没有闲着。
众多应用中,只使用过Eurekster,最具有潜力的25公司之一。Eurekster公司正在利用社群网络提供更富有个性化的搜索结果。它可以让用户使用搜索引擎创建一个社群网络,用户可以看到自己社群当中的其它人的兴趣爱好,这种模式和利用关键字及运算定位用户的搜索结果的模式类似,但它的不同之处在于,它是根据一个特定组群中人们的爱好在排列搜索结果的先后顺序。 事实上,基于此模式可能还可以走得更远,那就看用户需求和技术实现。
----
一开始我并没有非常明白ROLLYO是怎么回事,单从界面设计来讲她是非常成功的,恰到好处的红白配色比例,即便是在深更半夜也没有令我感到视觉疲劳,但是讲到她的作用机理,又不得不拿我前些日子介绍过的另一个社会化搜索引擎Jeteye出来......
其实两者在概念上是非常相似的,以用户参与(Jeteye是以jetpak,ROLLYO是以searchroll)来构建搜索数据。Jeteye的数据关联是通过jetpak的互相引用,而ROLLYO则是通过用户间互相订阅searchroll来完成,从ROLLYO的本意来看是要创建更用户导向的搜索环境,所以并没有向用户提供参与建设其他用户的searchroll的权限,至少目前没有,ROLLYO在这一点上声称是using only the sources you trust。
如果要说两者最大的区别,我想Jeteye还是以数据共享为主旨,而ROLLYO则是鼓励数据过滤,符合现在被极力鼓吹的attenuation is the next aggregation,而在我看来关键的不同是,Jeteye由于开放用户互相参与的权限,所以她的搜索还限于用户数据,提供各种搜索引擎也仅是作参考,而ROLLYO正儿八经地是用Yahoo!的搜索引擎提供数据,你在一个searchroll里搜索的关键字直接是从Yahoo!搜索引擎中按照searchroll所列出的最多25个的数据来源站点进行过滤后返回的,我自己瞎猜一下,ROLLYO名字何来,大约有几种可能,一是Roll Your Own Search Engine,抑或是YOYO(You're On Your Own),还是Roll Yo!(嗨!唷!),最有可能就是ROLL Yahoo!了,把Yahoo!卷巴卷巴大家分了吧~~~
rollyo的个性化搜索(via WebLeOn)非常吸引人。事实上,我一直希望能对我所订阅的Feed所对应的网站进行搜索,也就是搜索我的Blogroll,rollyo的出现部分满足了我的愿望。有了rollyo,从blogroll里找文章方便多了。不过rollyo限制每个searchroll只能包含25个网站,有点麻烦,webleon说yahoo也有类似服务,有空dig一下。
闲来无事就去del.icio.us上去发掘一番,今天看到了一个可以创建自己个性化搜索器的网站:Rollyo,虽然不是什么新事物,对我来说却是第一次见,而且感觉犹为特别,所以向大家推荐一下。
Rollyo将这个个性化搜索称为“Searchroll”,创建Searchroll非常简单,只要将相关网站加入列表(目前最大支持25个网站),并标上TAG就可以得到一个个性化的搜索器,它是针对你所加入的网站进行搜索,好像是用的yahoo的引擎,如果你觉得不满意也可以扩大到整个网络去搜索。
当然Rollyo最大的用处是你可以获得别人的Searchroll,对于浩瀚无垠的互联网信息,怎样缩小范围获得更准确的结果一直是一个头疼的问题,特别是目前SEO横行,无关信息、垃圾信息一搜一大堆的情况下,Rollyo的价值就更为突出,许多专业人士或对某项主题特别有研究的人,他们创建的Searchroll往往是最有价值的,可以帮助你迅速获得最有效的信息。
例如我想寻找web2.0方面的资讯,首先可以在它的Explore搜索web2.0,可以得到别人创建的一长串关于web2.0的个性化搜索器,随便选择一个进行搜索,就可以获得大量相关信息,非常实用。
当然Rollyo还提供了很多辅助工具,例如将浏览器书签直接加入到Searchroll,将Searchroll放入Firefox工具栏,将Searchroll放到你的网站上等等,如果你也想创建自己的个性化搜索器或者使用其他专业定制的搜索器,一定要来试一试。我随手创建了一个“web2.0在中国”的搜索器,大家不妨试用一下。也希望以后能涌现出利用google、baidu引擎来创建社会化个性搜索器的中文服务网站。
Rollyo的意思是“启动你自己的搜索引擎”。虽然它用的也是雅虎的搜索技术,但允许你把检索的网站限制在那些你相信能产生最佳效果的网址上,从而锁定你的查询。如果你想找关于面包的信息,那么你可以把搜索限制在一系列你认为能提供最佳相关信息的网址上,而不必在互联网的汪洋大海中只捞到一个“发酵的酸面团”。这种个性化设置的搜索引擎叫“searchroll” '
要创建一个searchroll,先登陆Rollyo网站(rollyo.com),你可以设定多达25个你认为和某个主题最为相关的网站。如果你不想手动输入要加进searchroll中的网站,也可以把浏览器里的书签上传到Rollyo,只挑选你要用的网址就行了。
创建一个searchroll后,你就可以反复用它来搜索与该主题相关的任何信息,其他访问Rollyo网站并对相同主题感兴趣的人也可以使用。同样,你也可以利用别人已经创建的searchroll。如果通过一个searchroll搜索仍然找不到自己想要的信息,只需点击一下就能把搜索范围扩大到整个互联网。
每一个searchroll都有自己的网络地址,因此你可以直接找到它,而不必在整个Rollyo网站中跋山涉水般寻找,你也可以把这个地址用电子邮件寄给别人。你甚至可以把searchroll加到Firefox网络浏览器工具栏的搜索引擎的下拉列表中去,这样不必先登陆Rollyo网站就能找到它在哪儿。
比如,我创建了一个关于我热爱的波士顿红袜棒球队(Boston Red Sox)的searchroll,里面有我最喜爱的25个关于波士顿红袜的网站,你不妨在rollyo.com/wmossberg/red_sox_nation上试一试。
Rollyo也包括由一些 “高级玩家”(High Rollers)创建的searchroll,这些是各个不同领域中的名人或专家。 例如女演员黛布拉?梅辛(Debra Messing)创建了一个关于在线购物的searchroll,设计师戴安?冯?弗斯腾伯格(Diane Von Furstenberg)创建了关于时装的searchroll,专栏作家兼活动分子亚里安娜?赫芬顿(Arianna Huffington)创建了一个政治博客的searchroll。
并不是每一次搜索都要用到Rollyo,但如果你经常在几个特定的主题范围内搜索,那就值得使用或创建一个关于这个领域的searchroll。
Pubsub则是完全不同的另一种工具,它能持续更新与某个特定主题相关的信息,搜索内容包括博客、被称为新闻组的在线讨论、SEC档案和新闻稿。
在一般的搜索中,你输入一个关键词,然后搜索引擎尝试在网址索引中找到与之匹配的项目,这是一个一次性的过程。而在PubSub搜索中,关键字会持续生效,搜索引擎会一直在不断变化的、从PubSub资源中收集到的数据流中寻找匹配项目。即使在输入关键字过后好几个月,只要匹配项出现,它就会在PubSub中跳出来通知你。
PubSub自称是一个“匹配引擎”,并宣称自己是“前景光明的”、“未来的”的搜索引擎——在可能尚未出现的数据中查找。比如,我去年夏天通过PubSub进行了一次搜索,直到昨天它还在报告最新搜索结果,这些信息在我开始搜索那会儿还没有上网。
要创建一个PubSub搜索器——公司称之为“预订”,先登录pubsub.com,输入一个或多个你想让Pubsub持续搜索匹配项的关键字。你可以有很多预订项,全部免费。
你可以访问PubSub的网站来查询结果,也可以通过下载一个“侧栏”模块把PubSub加到你的浏览器中,这个模块会在一个特殊窗口中列出PubSub查询的结果,一旦发现新的匹配项就会通知你。这些侧栏适用于Windows IE以及Windows、Macintosh和Linux上的Firefox。
PubSub也能把搜索限制在某些类型的资源上,比如,只限于新闻稿。PubSub希望在未来逐渐增加更多类型的资源。
一些主要的搜索引擎正在实验跟Rollyo类似的模式,你可以在某些管理博客概要和新闻网站的“RSS读者”程序中实现PubSub的某些功能。但Rollyo和PubSub十分好用,值得一看。
Labels: search engine
社会化搜索的探索之路——swicki案例
马国良
前不久一向标榜自己机器搜索强大的google先后推出了searchmash和Custom Search Engine两款社会化搜索服务,证明google对社会化搜索这一未来搜索市场主角的重视,更重要一点也证明社会化搜索是搜索引擎发展的必然所趋,google当然不愿意自己成为社会化搜索引擎领域的落伍者。Yahoo!、百度、live、google等传统搜索巨擎都先后加入社会化搜索阵营,证明社会化搜索的时代到来了。
这两天网络上开始讨论起Google已推出的基于Co-op的自定义搜索引擎服务——Custom Search Engine,google的CSE是针对个人和网站提供的专门搜索。好处是为用户提供可定自义搜索引擎服务,把几个网站的内容索引起来做成一个搜索引擎的优先选择,还可以自己命名搜索引擎的名字,为搜索引擎提供一些自己想要放上去的关键词和tag.其实提供类似服务的搜索引擎成熟模式已经有社会化搜索swicki、rollyo、PSS!以及Yahoo.com的Yahoo search builder、live search宏搜索,google这次其实在模仿和借鉴。deyeb CEO董一萌先生说deyeb也将在月末推出自己的定制搜索,大概也是指定要搜索的网站域范围,每行一个,添加相关主题的tag、关键词等,填写不包含那些关键和那些站点,搜索的名字和logo都是自己可以随心所欲等。虽说这里所说的各个搜索引擎外表非常相似,似乎原理也都相近,但是还是有微小的差别。本篇文章题目就是《社会化搜索的探索之路——swicki篇》,我个人的意见和董一萌先生一致:觉得swicki是最具社会化性质的搜索引擎,原因是 swicki是 “一个自动从你的搜索行为学会搜索的搜索引擎”。
一句话的定位
Google CSE相比没有任何新意,就是定制、指定范围搜索,提供搜索代码(怎么感觉和google adsense提供的搜索代码呢?),Google CSE的定位是“根据你特定的需求替你建一个特定的搜索”;rollyo也是,rollyo的定位是“建一个从你信任站点搜索的搜索引擎”,这个对于,这样能增加搜索结果的精确性,减少垃圾信息的干扰;PSS!旨在用户可以建自己的搜索目录,进而建立自己的搜索引擎,个人感觉个性化,还是不够点; Yahoo.com的Yahoo search builder和live search宏搜索都是定位在个性搜索,兴趣点搜索,定制搜索引擎指导搜索自己要想要搜索站点的内容;swicki的定位“一个向你学习的搜索引擎”,通过单个用户使用,用户的定制:包括对搜索范围以及搜索结果,用户对个人的搜索引擎作用的结果,将直接影响swicki,所以说swicki“一个向你学习的搜索引擎”。
Swicki是什么?
很多朋友第一眼看swicki可能会看不懂,swicki到底是什么?搜索引擎?却连一个搜索框都没有?确实有别人其他传统搜索引擎和社会化搜索引擎。打个比方大家就明白swicki是什么了?swicki就是博客的BSP(Blog Service Provider),swicki是一个搜索引擎服务提供商,即SSP(Searchengine Service Provider)。个人博客是一个非常个性化的东西,外表,用户可以利用各种模板套用甚至自己修改、做模板,一旦一个BSP能够提供足够吸引该用户的服务,用户可能会一直使用该BSP提供的服务,而且会一直用心去经营它。BSP的内容来源于每个用户,因为用户的对个人博客的投入相对较大、也较真实,往往博客的内容价值和质量高于论坛帖子和一般网站新闻。Swicki现在就是在做类似BSP 的SSP角色,为每个用户提供一个二级域名的搜索,虽然用户不能大幅度修改搜索外表,但是用户对搜索范围以及搜索结果几乎可以做到“随心所欲”的编辑。另外一点Swicki有别于rollyo的是,Swicki没有大门,只有“虚掩的小门”,进入的都是一个个很小的入口。小入口进入的是每个人的自由空间,而不是整个大社会。这种好像个人空间的个人搜索就是每个人的博客。Swicki除了特殊的搜索结果编辑外,再加上强调个人搜索模式,强调个人价值和作用应该未来网络发展的一个趋势,搜索引擎也是如此。个人搜索的价值如同博客一样,最主动的动力驱使出最有价值的东西,也就是社会化的力量。这就是为什么我们说 Swicki是最具社会化性质的搜索引擎。
Swicki的改进
Swicki的个人搜索还只有一个个简陋的外壳,个性化不足,也将限制个人搜索引擎的发展和普及。个人搜索应该是一个个很容易上手的个性搜索工具,也是一个个个性空间。强调个性只是为了挖掘主观动力的价值。同时个人搜索是个人为自己打造的一个个有用的垂直搜索引擎,如何构建个人的垂直引擎呢?收藏应该是最好的整理个人有用网站的方式,按照分类来收藏,个人慢慢积累,最终每个人都可以建一个非常专业的垂直搜索引擎。收藏(自己认为有价值的网站)→进入个人搜索网站列表,这样能提高用户搜索精确率。每个的搜索引擎应该是可以分享的,建立一个个搜索引擎兴趣圈,把相近的个人搜索引擎归在一起,类似友情链接的分享方式。另外例如教育博客或者教育站长,可以为自己的博客或者网站提供教育专业搜索,只要把个人搜索代码加入博客或者网站就可以。这样可以把搜索引擎更大的价值挖掘出来,一个Swicki等于无数个个性的垂直搜索引擎,而收藏帮助用户不断完善他的搜索引擎。用户是非常乐意用自己建立的搜索引擎,并把它挂在自己博客和网站的最显眼地方。
Labels: search engine
Monday, June 11, 2007
发现搜索的价值:走出语义搜索误区
这股范式转型潮流由多条支流组成,其中一个支流是包含本地化搜索、社区内容搜索、知识问答社区等在内的社会化搜索,另一个支流则是人工智能、模式识别、语义分析、神经网络等智能搜索。第三代搜索,作为对以Google为代表的第二代搜索范式的超越或者说革新,时下正逼近一个重要的时间拐点。这股范式转型潮流由多条支流组成,其中一个支流是包含本地化搜索、社区内容搜索、知识问答社区等在内的社会化搜索,另一个支流则是人工智能、模式识别、语义分析、神经网络等智能搜索。
可以说,就技术门槛而言,智能搜索代表了下一代搜索的主流趋势。但鉴于基于神经网络、人工智能的搜索耗资巨大,目前还处在试验阶段,尚无一家成型的搜索引擎上线;至于全球搜索界穷20年之力埋首研发的自然语言分析或者语义分析,由于语言本身的复杂性,其结果及性能迄今还不能解决现实世界的问题,也因此,迄今还没有一家完全基于语义分析的搜索引擎获得商业成功。
语义搜索的局限
完全采用语法和词汇原则来理解文字信息的语义搜索的一大局限,是不能处理例如双关语、多义词等模糊信息。这是因为计算机本身缺乏理解能力,尤其是缺乏理解不确定性信息或模糊信息的能力,所以当计算机尝试通过解析整段话来提取含义时,就会颇为棘手。一些高级的系统能够建立一套使机器解决不确定性所遵循的原则。但是,其指令集极为烦杂而且难以维护,基本没有可操作性。
与基于关键字的搜索方法一样,语义搜索方法也不能确定思想的相对重要性。换句话说,计算机会给一句话中的不同词汇分配相同的重要性值,而这与自然语言的实际内涵可能大相径庭。
固然,在最好的情况下,语义搜索方法可以处理少数简单的句子,但在采用包含大量概念的大型文件时,要从整段话、整篇文章中提取含义,其语言模式就只能望洋兴叹了。由于语义分析是基于真/假决策树和规则结构进行推理的,一个不正确的决策或者一个未知的查询的出现,会导致整个分析全盘皆错。
此外,语义分析都是基于特定语言及其语法结构的,这意味着它在俚语或语法方面非常容易出错。而且一旦有新单词或者变更出现,则必须对系统进行调整,从而保证系统能够理解这些新单词或变更,对系统进行拓展是一项复杂的工程。通常,语义搜索引擎只能支持有限的一些语言,如果要增加一种新的比较难的语言,则会产生很多问题。此前国内的问一问、21ilink、悠游等基于自然语言处理的搜索引擎之所以昙花一现,然后即迅速地被甚嚣尘上的第二代关键词搜索所淹没,与此有关。
另一种方法
与完全基于语法结构分析的语义搜索不同,以Autonomy为代表的核心概念匹配技术并不单纯依赖于一种语言的语法结构,而是把文字当作语意的抽象符号或者另一种“类型”的信息,采用可预测的统计词方式表示概念和功能,并通过有意义的概念词出现的上下文环境(而不是通过严格的语法定义)来形成对该概念词的理解,以此确定文档中每个主题的相关性及重要性。由于其系统由所输入的实际数据驱动,而不是由与内容无关的辅助规则所驱动,所以, Autonomy的系统可以支持基于俚语、行业术语、自然语言的检索。
因为同样的原因,Autonomy还能够不受语言语种限制(支持超过80种语言),支持任意信息片断的检索,只要该语言的信息足够多,就可以让系统形成对该语言的理解。例如将一句话、一段或者整页文本作为输入的搜索条件,由此可返回与搜索条件概念相关的结果,这些结果可按照概念相关性或文档上下文关联排序。Autonomy 的技术甚至能自动检测输入文档的语言并改变相应配置以自动处理每一种语言。
Autonomy的技术内核,是一个被称为IDOL的智能信息处理层。IDOL由动态推理引擎 (DRE)、分类服务器、用户服务器等模块组成,DRE 可实现概念识别、自动摘要、有效识别、自动超链接、自然语言检索等核心操作,分类服务器可实现自动聚类、自动分类、自动目录生成等功能操作,用户服务器则可以实现个人化信息创建、个性化信息提示、个性化信息训练、专家定位等个性化操作。
可以说, IDOL提供了一个对语言模式进行文字分析、进而推断出有序概念的智能内核。正是以此为基础,Autonomy才能够发展出一整套基于“模式匹配”的功能应用,比如二维岛图、二维趋势图、三维立体图等图形化结果,比如自动建档、社区及协作、专家搜索、信息推送等行业应用,比如电子通讯和管理技术的安全监控、诉讼及风险管理自动化的Aungate,比如下一代呼叫中心技术Qfiniti(现在是Autonomy etalk部门的一部分),比如视频关键帧识别技术和语音识别技术,如此等等。而这些Autonomy早在上世纪90年代末即已研发成熟并投入使用的搜索应用,正是眼下第三代搜索潮流中最被看好的主流应用。
Labels: search engine, semantic web
几个语义搜索站点和一些想法
http://www.kylogs.com/blog/index.php/archives/268.html
从Read/Write Web上看到几个语义搜索的实践者。Cognition Search, PowerSet,和 Lexxe。我第一个感觉是在忽悠。因为网络上靠忽悠,炒概念的人实在是太多了。这样的忽悠者,米国不比中国少。毕竟骗子处处有,被骗的傻子也处处有。
试了这几个站点, PowerSet并没有公开的发布它的搜索 框,而是需要申请才有机会去体验一下它号称的Natural Language Search。据体验过的人说,搜索的时候词汇是限定的,而且其收录的站点也只是那些具有超高质量文章的站点。老实说,我看到Natural Language Search几个字的时候真是忍不住想笑,罢了罢了,还是要对实践者表示致敬。虽然不前不清楚它是在实践还是在忽悠。
Cognition Search有些低调,也提供了搜索 框,但仅限于某几个特定的领域,Case Study ,Goverment, Political Blogs,能搜索的网站也是固定的而且及其有限。有一点比较有意思的是,当你搜完之后,它会试着给出一些你搜的关键词(往往搜索串的是谓语和宾语)的意 义的备选项。你可以根据它给定的备选项来明确某个关键词的背后涵义,以帮助系统准确的理解搜索者的真正意图。Cognition Search做的工作蛮有意思的。
Lexxe给出了类似于Google的简洁的搜索界面,号称 Powered By Advanced Natural Language Technology。我试了几个超简单英文疑问句,它的理解能力还是比较低下的,至于搜索结果,可能是索引量太少的缘故,惨不忍睹。有意思的是这个站点 的图标是一个中文的“猎”字。
其实自然语言处理这回事,要一下子出来一个完全的解决方案是不现实的,但是在某一个小的领域,某一个小的应用还是不断的在发展的。当然了,如果目前 的Web是语义Web了,我们理解网络上的文本信息也用不着自然语言处理这么麻烦。许多人在争论,哪一个成本更低一点,更加现实一点。这样的争论看来有些 好笑,不管怎么看,这两个都是那么的不现实。但是,如果深入到其中的领域,你兴许就能体会到里面发生的深刻的变化和巨大的进步。类似于我这类的井底之蛙就 只能坐着看看热闹了。
Labels: search engine, semantic web
Google启用通用搜索及试验搜索结果页
据GOS报道,昨天Google在总部搞了个搜索学(Searchology)大会,探讨了搜索技术的过去、现在和未来(实话实说?),他们说搜索还是个很困难的课题,有许多问题要解决,但搜索仍将是Google的核心竞争力。
同时,Google发布了新设计的“通用搜索”(Universal search)结果页面,上面把新闻、图片、视频、图书甚至本地的一些内容都当作正常的搜索结果按其重要程度列出,而不再是只列出网页结果,也就是说结合 了所有的内容源,要“最精确地”满足用户的搜索需求。
GOS报道中给出的例子搜索词“Nosferatu”,结果页上确实有视频,来自Google video,同时,比GOS的抓图更进一步,原来显示多少条结果的那个蓝条也进行了重新设计,变成漂亮的有一点3d效果的条,上面会显示Web News Image和Video,具体显示什么似乎各个词不太一样。
而原来出现在搜索框上的Web image等特定搜索页的链接已经和Google的其他服务一起跑到了页面的左上角,上面列出了所有的服务,最前面列出用户最常用的──应该是登录后会根 据个人使用情况动态变化,这个设计很有用,最后的more是个下拉菜单,里面的其他的那些。这个设计在Gmail里也有,中文版似乎也有了。据说这个设计 将出现在所有Google服务上。
Google还推出了搜索实验页,专门让大家看各种设计的结果页,有按时间线显示的,显示在地图上的,还有键盘快捷键(又是Vim规则,充分说明了Vim的影响力
Vim好就好在低可当记事本,高可以编程控制,中间还有无数命令可用,
并且自由开源,学习一次终生受益,各硬件平台统吃,永无找Key之烦恼
──采自水母新软版,略改。
另外还有把搜索导航条设计到左边或右边的实现。
按Gos的报道,Google还将试验一定程度的语义搜索,即当用户输入一串搜索词句后,主动猜测它的中心意思,变换搜索词,再来提交结果,并且还将试验翻译用户搜索词,用其他11种语言进行搜索。不知道这些猜测含义的工作能走到哪一步,是否还要像翻译一样,承认“100%正确翻译的理想仍然没有实现”,然后加上用户提交校正的按钮呢?
这些还是比Google中国推出的东西要吸引人,像最近推出的相关主题,大家试了后会看到那个more:选项,自然会在more前面加上其他词试一下,不想结果上方的相关还是都给加了“车主”什么的,犯晕啊。现在英文搜索上也有“Searches related to:”,倒没有这个more算法。
Labels: Google, search engine
Google推出自定义搜索 抢垂直搜索饭碗
http://news.csdn.net/n/20061024/96699.html
北京时间10月24日消息,据国外媒体报道,今天Google推出一款用户可自定义的搜索引擎。Google自定义搜索引擎允许用户选择希望加入到搜索中的网站,而且用户还可以通过为网站设定“标签”,这样用户就可以很快得到需要北京时间10月24日消息,据国外媒体报道,今天Google推出一款用户可自定义的搜索引擎。Google希望通过这一产品为自己的搜索广告业务打开一个新市场。
Google的搜索引擎产品经理Shashi Seth说,“现在人们可以不上Google网站就可以直接进行搜索了。”
Google自定义搜索引擎允许用户选择希望加入到搜索中的网站,而且用户还可以通过为网站设定“标签”,这样用户就可以很快得到需要的信息,而且搜索结果将更为准确。同时这款产品的盈利模式依然不变。
在此之前,一家叫做Rollyo的公司就已推出了类似的服务。Google推出自定搜索应该是参照了Rollyo概念。
Google推出该产品的目的是其他的一些垂直型搜索引擎竞争,比如工作搜索等。
Labels: search engine
Rollyo:社会化的个性搜索器
Rollyo将这个个性化搜索称为“Searchroll”,创建Searchroll非常简单,只要将相关网站加入列表(目前最大支持25个网站),并 标上TAG就可以得到一个个性化的搜索器,它是针对你所加入的网站进行搜索,好像是用的yahoo的引擎,如果你觉得不满意也可以扩大到整个网络去搜索。
当然Rollyo最大的用处是你可以获得别人的Searchroll,对于浩瀚无垠的互联网信息,怎样缩小范围获得更准确的结果一直是一个头疼的问题,特 别是目前SEO横行,无关信息、垃圾信息一搜一大堆的情况下,Rollyo的价值就更为突出,许多专业人士或对某项主题特别有研究的人,他们创建的 Searchroll往往是最有价值的,可以帮助你迅速获得最有效的信息。
例如我想寻找web2.0方面的资讯,首先可以在它的Explore搜索web2.0,可以得到别人创建的一长串关于web2.0的个性化搜索器,随便选择一个进行搜索,就可以获得大量相关信息,非常实用。
当然Rollyo还提供了很多辅助工具,例如将浏览器书签直接加入到Searchroll,将Searchroll放入Firefox工具栏,将 Searchroll放到你的网站上等等,如果你也想创建自己的个性化搜索器或者使用其他专业定制的搜索器,一定要来试一试。我随手创建了一个 “web2.0在中国”的搜索器,大家不妨试用一下。也希望以后能涌现出利用google、baidu引擎来创建社会化个性搜索器的中文服务网站。
Labels: Rollyo, search engine
社会化个性搜索:Rollyo
星期三, 九月 28日 2005
Rollyo http://www.rollyo.com/
yahoo my web2.0 http://myweb2.search.yahoo.com/
这是个让人一见到就印象深刻的服务,Rollyo可以让我们创建、使用及分享不同的搜索档案。你不但可以控制自己的搜索范围,更可以通过使用其他专业人士所创建的搜索档案,来提高搜索效率,避免Spam的干扰。
Rollyo里的搜索档案被叫做Searchrolls,是由用户创建的一个网站列表。把几个内容相关的网站加入列表,起好名字并选择分类并加上 Tags,一个Searchroll就完成了。使用这个Searchroll,搜索将被限制在它的网站列表中所列出的网站之内。Searchroll可以 自己使用,也可以公开分享。当然,你也可以方便的搜索、收藏其他用户的Searchroll。
假设有一个Rollyo用户是某一方面的专家,那他所创建的此方面的Searchroll对其他用户来说,便是非常宝贵的资源。其他用户可以利用专家的 Searchroll进行更快速、更准确的搜索。当然,我们一开始并不知道哪个用户的Searchroll是有价值的,所以Rollyo里也有用户评价系 统选出的High Rollers,帮助用户更快地找到专家用户。
Rollyo虽说是一个刚刚推出的服务,但是已经有了不少辅助工具。Add to Firefox让你可以方便的把Searchrol加入Firefox的搜索栏;Import Bookmarks则可以让你导入书签快速建立Searchroll。
Yahoo几个月前推出的My Web也有类似的功能,不过Yahoo所构建的系统多少有点太过于复杂,在没有足够好友和搜索量的情况下,也不能得到很好的效果。还是Rollyo以网站列表为基础,直接分享Searchroll来的直接明了。
Labels: search engine
Thursday, June 07, 2007
语义搜索引擎综述
摘要:本文综述了搜索引擎发展的现状以及工作原理、评价指标等主要技术特点。同时引出了语义搜索引擎在搜索引擎发展方面的重要地位。
关键字:搜索引擎、语义搜索
1.网络搜索引擎的现状
搜索引擎在互联网的重要地位由来已久。Yahoo 作为门户网站奇迹般崛起所依靠的正是搜索引擎,Google 也以搜索引擎的技术创新、竞价排名和专业风格创造了新的奇迹。在国内,百度也在很短的时间里凭借搜索引擎取得很大成功。
搜索引擎技术及业务模式的持续创新,不仅为互联网 注入了活力,而且其自身的价值正被重新审视和评估。互联网的发展使得信息短缺的问题被信息泛滥所取代,世界也已从信息时代走进信息经济时代,这两者的区别 在于,前者强调信息本身的价值,只要解决信息资源短缺就会带来价值的提升;后者认为信息并不稀缺,只有通过对信息的甄别、加工提纯和挖掘才能带来价值的提 升。
据中国国家互联网中心(CNNIC)2005年1月发布的第15次互联网发展统计报告[[1]],我国的网络用户有9400万人,比2004年6月发布的14次报告又增加了700万。在用户经营使用的网络服务中,搜索引擎仅次于电子邮箱排在第2位。有98.5%的用户上网最主要的是获取信息,通过搜索引擎获取信息的占70.7%,搜索引擎成为未知状态下发现有效信息的最有效方式。
2.网络搜索引擎的工作原理
搜索引擎的原理,可以看作三步:
a) 从互联网上抓取网页;
b) 建立索引数据库;
c) 在索引数据库中搜索排序。
1. 从互联网上抓取网页
利用能够从互联网上自动收集网页的Spider系统程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。
2. 建立索引数据库
由分析索引系统程序对收集回来的网页进行分析,提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的所有关键词、关键词位置、生成时间、大小、与其它网页的链接关系等),根据一定的相关度算法进行大量复杂计算,得到每一个网页针对页面文字中及超链中每一个关键词的相关度(或重要性),然后用这些相关信息建立网页索引数据库。
3. 在索引数据库中搜索排序
当用户输入关键词搜索后,由搜索系统程序从网页索 引数据库中找到符合该关键词的所有相关网页。因为所有相关网页针对该关键词的相关度早已算好,所以只需按照现成的相关度数值排序,相关度越高,排名越靠 前。最后,由页面生成系统将搜索结果的链接地址和页面内容摘要等内容组织起来返回给用户。
3.网络搜索引擎的评价指标
评价搜索引擎的主要指标有查全率、查准率、响应时间、覆盖范围、用户使用方便性等等。
1. 查全率(Recall)
查全率又叫召回率,是指检索出的相关文档占全部相关文档的比率。即用户通过搜索引擎所获取的有用信息与整个Internet中相关信息的比率。
2. 查准率(Precision)
查准率是指获取的相关文档与获取文档的比率。即用户通过搜索引擎所获取的真正是用户需要的信息占获取信息的比率。搜索引擎的查准率是个复杂的概念,一方面表示搜索引擎对搜索结果的排序能力,另一方面却体现了搜索引擎对垃圾网页的抗干扰能力。
3. 响应时间(Response Time)
响应时间是指用户发出查询请求后到看到查询结果的这段时间。
4. 覆盖范围(Coverage)
覆盖范围是指搜索引擎索引的Web页面占整个Internet中页面的比例。
5. 用户方便性(Convenience)
用户方便性包括查询接口是否直观、易于使用、查询语法是否丰富,显示结果是否易于查看等。
4.网络搜索引擎的主要技术
网络搜索引擎做为信息检索系统的一个分支,理所当然的涉及到信息检索方面的技术,同时它做为一个独立、成熟的领域也有自己的技术空间:
1. 目录检索和全文检索
传统的搜索引擎一般使用两种技术来实现信息检索:
一是使用网站分类技术实现目录检索,即把网站进行树状的归类,登陆的网站属于至少一个类别,对每个站点都有简略的描述。Yahoo采用了这种方法。为了分类科学准确,需要有一支各科人才组成的维护队伍。
二是使用全文检索技术。全文检索技术处理的对象是文本,它能够对大量文档建立由字(词)到文档的倒排索引,在此基础上,用户使用关键词来对文档进行查询时,系统将给用户返回该关键词的网页。
2. 索引文件结构
全 文检索的两个关键技术是索引和检索。检索又是基于所建立的索引结构进行的。索引文件主要分为正向索引和倒排索引。正向索引是基于文档的,每一个文档对应一 个索引文件,其中记录着这个文档中出现的词。倒排索引是基于词汇表的,每一个特征词对应一个倒排索引,其中记录着所有出现过这个词的文档。目前,技术比较 成熟、也是公认效率较高的索引存储结构是倒排文件。需要明确的是,中文的构词方式、句法、语法都与英文有很大区别,因此,不同于英文全文检索的索引方法, 中文全文检索中主要的建立索引方法是字索引和词索引。字索引保证了高的召回率,不会出现漏查错误,但是会出现多查和误查。检索结果中会出现不少与检索意图 无关的条目。另外,基于字索引的全文检索的检索效率也比较低。而词索引保证了较高的查准率和检索效率,但是由于中文分词能力的局限,导致基于词索引的全文 检索必定会存在漏检情况。另外,对于未登陆词,词索引显得力不从心。现存比较实用的中文信息检索系统一般都结合使用了字词混合索引,或者扩展的词索引,来 保证召回率和查准率。
网络搜索引擎由于各自的策略不同,在选择索引对象的内容时也有不同。有些搜索引擎对于信息库中的页面建立全文索引,有些只建立摘要部分,或者每个段落前面部分的索引,还有些搜索引擎(如Google)建立索引的时候,同时考虑超文本的不同标记所表示的不同含义。如粗体、大字体显示的东西往往比较重要;放在锚链中的信息往往是它所指向页面的信息的概括,所以用它来作为它所指向的页面的重要信息。Google,Infoseek还在建立索引的过程中收集页面中的超链接。这些超链接反映了收集到的信息之间的空间结构。利用这些结果信息可以提高页面相关度判别时候的准确度。
3. 数据源文件的分布策略
搜索引擎的数据源文件主要包括索引文件和原文档。目前,数据源文件的分布策略主要有集中存放和分布式存放。文献[2]指出Google就 是采用了集群的方式集中存放数据源文件,事实上,几乎所有的商业搜索引擎都采用集中存放的方式,这是因为分布式存放策略有一个硬伤,就是搜索请求从一个端 点传送到另外一个端点消耗的时间让用户难以忍受。但是,随着互联网上信息的急剧膨胀,改进后的分布式策略是最终的解决方案。
4. 索引大文件的存放策略
倒排文件是一个大文件,这是因为倒排文件中存放的记录(Hit)表示的是文档中出现本特征词的状况。目前的商业搜索引擎的文档集中的文档数量非常之大,因此倒排文件的记录数也会很大,最终导致倒排文件的尺寸非常大。
对于大文件首先考虑的是压缩,像是Google存放的索引文件就是经过压缩的。好的压缩算法同时要求压缩比尽可能高、查找压缩文件容易、解压缩时间短。即使压缩之后的文件仍然大到不能以独立的文件形式存放,目前有两种分离大文件为多个小文件的策略:
一是基于文档集的分离。主要是将文档集分成有限个子集,对于每一个子集建立各自的索引文件,检索过程就演变为对多个文档子集的检索,最后做的合并处理。
一是基于索引文件的分离。即是将索引大文件分为有限个子文件,并设计一张表记录这种分离情况,当要检索这个索引文件时就查找这张表,根据表的记录去查找每一个子文件。文献[3]指出Google将索引大文件分离为若干个小文件,每一个小文件都以独立的linux文件存放,通过linux系统管理这些小文件,这正是这个策略的一种表现。
5. 排序算法
各种搜索引擎的技术改进和优化,都直接反应到搜索结果的排序上。许多搜索引擎都在进一步研究新的排序方法,来提升客户的满意度。目前,不同搜索引擎基于不同的搜索策略设计有多种不同的排序算法,以Google为例,它采用很多种排序算法支持搜索结果,其中最典型的代表有PageRank和HillTop,这两种都属于超链接分析技术。
5.语义搜索的兴起
目前实用化的信息检索系统主要基于人工分类目录或 关键词匹配。前者对海量信息资源的揭示的效率不高、深度有限;后者在信息的语义和语用的揭示上有局限性。信息检索系统在智能处理能力上的缺乏,导致这些工 具远远不能满足用户的需求。如何解决好诸如信息组织、知识表示、机器理解与人机交互等问题,对于提高信息利用的效率,是非常重要和迫切的。近年来,语义网 的提出为解决这些问题提供了锲机,由于语义网中的资源被结构化,能被计算机所理解和识别,这样提供了改进传统搜索技术的机会。语义检索的目的是通过从语义 网上获取的数据增强并改进传统的搜索结果(基于信息检索技术)。 它实现了用户检索请求的本体化,整个搜索引擎像领域专家一样,不仅给出查询结果,还给出了与检索请求相关的资源,大大提高检索的精度和覆盖率;实现了本体 层次的检索,突破了关键词检索局限于形式的固有缺陷。它的出现提高了用户的满意度,减少了不相关的返回结果,提高了检索的精度和覆盖率。
最初人们通过代表语义的HTML标签来改造网页,主要有GDA系统和
SHOE(SimpleHTMLOntologyExtensions)系统等。但这些系统的不足是仅能处理经过HTML标签改造的网页。
XML是非常有前途的语言,因为它将网页的内容、结构和描述分离,并且非常适合知识的描述。但是XML通过它的句法结构仅能描述一些语义属性。
语义网络的建立使得以语义为基础的搜索引擎同时可 以建立起来。在语义搜索引擎中,每一个查询都在一些本体的上下文范围内执行,来自本体的一些指南可以提高检索的准确性。在语义检索中,使用的是概念匹配, 即自动抽取文档的概念,加以标引,用户在系统的辅助下选用合适的词语表达自己的信息需求,然后在两者之间执行概念匹配,即匹配在语义上相同、相近、相包含 的词语。
6.语义搜索当前的应用
当前基于ontology 的语义检索系统已经得到了广泛的关注和应用,出现了一系列优秀的应用系统,其中典型的有两个:SWOOGLE——语义网中的基于蜘蛛网的检索系统,系统从每个搜索到的文本中抽取本体,根据本体之间的相关度来比较文本之间的关系;TUCUXI(InTelligent Hunter Agent for Concept Understanding and LeXical ChaIning),该系统根据查找的本体在网页上爬行,决定哪种网页最满足需求。特别的,TUCUXI 判断文档的相关性是同Map of Meanings 比较用户所查询的相关本体。Map of Meanings 语义丰富,用来对资源文本的表达。TUCUXI 采用了MOMIS 公用字典来表征用户查询的本体。在语义网中,基于Ontology 的语义检索搜索引擎有SHOE、OntoBroker、OntoSeek、WebKB、Corese。
7.总结
语义搜索引擎是未来搜索引擎发展的方向,它的发展主要受限于语义web的发展以及自然语言处理技术。语义搜索引擎设计的最终目标是让计算机具有人的智能,以解决问题的形式返回给用户。语义搜索引擎设计的当前目标是让计算机返回的结果更有针对性、准确性。
Labels: search engine
用Lucene构造简单搜索
Lucene是一个开源世界里最有名的搜索引擎包,关于它的介绍现在网络上也有很多了,特别是车东的文章http://www.chedong.com/tech/lucene.html,网上流传至广。现在还有一本《Lucene In Action》的电子书是详细介绍的Lucene,可以down下来看。今天先来对硬盘文件实现简单的索引和搜索功能。
用Lucene建立索引步骤:
- [1]指定索引源文件夹(dataDir)和索引的文件夹(IndexDir);
- [2]构造一个IndexWriter:IndexWriter构造器有三个参数,其中第一个参数可以是Lucene内建的类 Directory,也可以是File类型的文件夹路径,还可以是String类型的文件夹路径。第二个参数为语法分析器Analyzer,Lucene 自带了几个分析器的,但是对中文支持都不是很好,我在网上找了两个,效果还不错。待会将放下面供大家下载。这个参数的指定,比如我用自己的 CWordAnalyzer可以直接用new CWordAnalyzer()。最后一个参数是要注意的,Lucene Api解释为“true to create the index or overwrite the existing one; false to append to the existing index”,就是说在这里设定是否增量增加索引,在开发的时候得考虑了,设true将导致每次索引都删除原索引重建,但是如果原来不存在索引而设置为 false也将导致lucene抛出找不到指定文件的错误。
- [3]构造Document,通过add方法加入字段:
- Document doc = new Document();
- doc.add(Field.Text("contens",new FileReader(f)));
- doc.add(Field.UnIndexed("filename",f.getCanonicalPath()));
- [4]IndexWriter通过addDocument(doc)加入document对象,此时lucene将启动分词器对Document对象进行分词索引;
- [5]调用IndexWriter的optimize方法对索引进行优化,因为在索引过程中难免产生文件碎屑,该方法对文件进行优化可以提高检索效率;
- [6]关闭IndexWriter:IndexWriter.close()。
到此索引建好了,开始搜索部分。
用Lucene进行搜索:
- [1]创建IndexSearcher实例,其构造方法有三个,单参数,可以用String形式的索引文件夹路径;
- [2]创建Query :
- Query query = QueryParser.parse(q,"contents",new Analyzer());
- Hits hits = indexwriter.search(query)
其中q为查询字符串,“contents”为查询字段。
[list][3]搜索:
hits由Document类型组成。可以通过hits.doc(i)获取具体的Document对象
可以看到用lucene进行索引和搜索都很简单。
| je-analysis.rar | ||
| 描述: | 极易分词,analyzer是MMAnalyzer | 下载 |
| 文件名: | je-analysis.rar | |
| 文件大小: | 877 KB | |
| 下载过的: | 文件被下载或查看 230 次 | |
| segment.rar | ||
| 描述: | 来自台湾的分词,analyzer为CWordAnalyzer | 下载 |
| 文件名: | segment.rar | |
| 文件大小: | 1 M | |
| 下载过的: | 文件被下载或查看 244 次 | |
Labels: Java, Lucene, search engine
Lucene:基于Java的全文检索引擎简介
Lucene是一个基于Java的全文索引工具包。
Lucene不是一个完整的全文索引应用,而是是一个用Java写的全文索引引擎工具包,它可以方便的嵌入到各种应用中实现针对应用的全文索引/检索功能。
Lucene的作者:Lucene的贡献者Doug Cutting是 一位资深全文索引/检索专家,曾经是V-Twin搜索引擎(Apple的Copland操作系统的成就之一)的主要开发者,后在Excite担任高级系统 架构设计师,目前从事于一些INTERNET底层架构的研究。他贡献出的Lucene的目标是为各种中小型应用程序加入全文检索功能。
Lucene的发展历程:早先发布在作者自己的www.lucene.com,后来发布在SourceForge,2001年年底成为APACHE基金会jakarta的一个子项目:http://jakarta.apache.org/lucene/
已经有很多Java项目都使用了Lucene作为其后台的全文索引引擎,比较著名的有:
- Jive:WEB论坛系统;
- Eyebrows:邮件列表HTML归档/浏览/查询系统,本文的主要参考文档“TheLucene search engine: Powerful, flexible, and free”作者就是EyeBrows系统的主要开发者之一,而EyeBrows已经成为目前APACHE项目的主要邮件列表归档系统。
- Cocoon:基于XML的web发布框架,全文检索部分使用了Lucene
-
Eclipse:基于Java的开放开发平台,帮助部分的全文索引使用了Lucene
对于中文用户来说,最关心的问题是其是否支持中文的全文检索。但通过后面对于Lucene的结构的介绍,你会了解到由于Lucene良好架构设计,对中文的支持只需对其语言词法分析接口进行扩展就能实现对中文检索的支持。
Lucene的API接口设计的比较通用,输入输出结构都很像数据库的表==>记录==>字段,所以很多传统的应用的文件、数据库等都可以比较方便的映射到Lucene的存储结构/接口中。总体上看:可以先把Lucene当成一个支持全文索引的数据库系统。
比较一下Lucene和数据库:
| Lucene | 数据库 |
索引数据源:doc(field1,field2...) doc(field1,field2...) | 索引数据源:record(field1,field2...) record(field1..) |
| Document:一个需要进行索引的“单元” 一个Document由多个字段组成 | Record:记录,包含多个字段 |
| Field:字段 | Field:字段 |
| Hits:查询结果集,由匹配的Document组成 | RecordSet:查询结果集,由多个Record组成 |
全文检索 ≠ like "%keyword%"
通常比较厚的书籍后面常常附关键词索引表(比如:北京:12, 34页, 上海:3,77页……),它能够帮助读者比较快地找到相关内容的页码。而数据库索引能够大大提高查询的速度原理也是一样,想像一下通过书后面的索引查找的速度要比一页一页地翻内容高多少倍……而索引之所以效率高,另外一个原因是它是排好序的。对于检索系统来说核心是一个排序问题。
由于数据库索引不是为全文索引设计的,因此,使用like "%keyword%"时,数据库索引是不起作用的,在使用like查询时,搜索过程又变成类似于一页页翻书的遍历过程了,所以对于含有模糊查询的数据库服务来说,LIKE对性能的危害是极大的。如果是需要对多个关键词进行模糊匹配:like"%keyword1%" and like "%keyword2%" ...其效率也就可想而知了。
所以建立一个高效检索系统的关键是建立一个类似于科技索引一样的反向索引机制,将数据源(比如多篇文章)排序顺序存储的同时,有另外一个排好序的关 键词列表,用于存储关键词==>文章映射关系,利用这样的映射关系索引:[关键词==>出现关键词的文章编号,出现次数(甚至包括位置:起始 偏移量,结束偏移量),出现频率],检索过程就是把模糊查询变成多个可以利用索引的精确查询的逻辑组合的过程。从而大大提高了多关键词查询的效率,所以,全文检索问题归结到最后是一个排序问题。
由此可以看出模糊查询相对数据库的精确查询是一个非常不确定的问题,这也是大部分数据库对全文检索支持有限的原因。Lucene最核心的特征是通过特殊的索引结构实现了传统数据库不擅长的全文索引机制,并提供了扩展接口,以方便针对不同应用的定制。
可以通过一下表格对比一下数据库的模糊查询:
| Lucene全文索引引擎 | 数据库 | |
| 索引 | 将数据源中的数据都通过全文索引一一建立反向索引 | 对于LIKE查询来说,数据传统的索引是根本用不上的。数据需要逐个便利记录进行GREP式的模糊匹配,比有索引的搜索速度要有多个数量级的下降。 |
| 匹配效果 | 通过词元(term)进行匹配,通过语言分析接口的实现,可以实现对中文等非英语的支持。 | 使用:like "%net%" 会把netherlands也匹配出来, 多个关键词的模糊匹配:使用like "%com%net%":就不能匹配词序颠倒的xxx.net..xxx.com |
| 匹配度 | 有匹配度算法,将匹配程度(相似度)比较高的结果排在前面。 | 没有匹配程度的控制:比如有记录中net出现5词和出现1次的,结果是一样的。 |
| 结果输出 | 通过特别的算法,将最匹配度最高的头100条结果输出,结果集是缓冲式的小批量读取的。 | 返回所有的结果集,在匹配条目非常多的时候(比如上万条)需要大量的内存存放这些临时结果集。 |
| 可定制性 | 通过不同的语言分析接口实现,可以方便的定制出符合应用需要的索引规则(包括对中文的支持) | 没有接口或接口复杂,无法定制 |
| 结论 | 高负载的模糊查询应用,需要负责的模糊查询的规则,索引的资料量比较大 | 使用率低,模糊匹配规则简单或者需要模糊查询的资料量少 |
全文检索和数据库应用最大的不同在于:让最相关的头100条结果满足98%以上用户的需求
Lucene的创新之处:
大部分的搜索(数据库)引擎都是用B树结构来维护索引,索引的更新会导致大量的IO操作,Lucene在实现中,对此稍微有所改进:不是维护一个索 引文件,而是在扩展索引的时候不断创建新的索引文件,然后定期的把这些新的小索引文件合并到原先的大索引中(针对不同的更新策略,批次的大小可以调整), 这样在不影响检索的效率的前提下,提高了索引的效率。
Lucene和其他一些全文检索系统/应用的比较:
| Lucene | 其他开源全文检索系统 | |
| 增量索引和批量索引 | 可以进行增量的索引(Append),可以对于大量数据进行批量索引,并且接口设计用于优化批量索引和小批量的增量索引。 | 很多系统只支持批量的索引,有时数据源有一点增加也需要重建索引。 |
| 数据源 | Lucene没有定义具体的数据源,而是一个文档的结构,因此可以非常灵活的适应各种应用(只要前端有合适的转换器把数据源转换成相应结构), | 很多系统只针对网页,缺乏其他格式文档的灵活性。 |
| 索引内容抓取 | Lucene的文档是由多个字段组成的,甚至可以控制那些字段需要进行索引,那些字段不需要索引,近一步索引的字段也分为需要分词和不需要分词的类型: 需要进行分词的索引,比如:标题,文章内容字段 不需要进行分词的索引,比如:作者/日期字段 | 缺乏通用性,往往将文档整个索引了 |
| 语言分析 | 通过语言分析器的不同扩展实现: 可以过滤掉不需要的词:an the of 等, 西文语法分析:将jumps jumped jumper都归结成jump进行索引/检索 非英文支持:对亚洲语言,阿拉伯语言的索引支持 | 缺乏通用接口实现 |
| 查询分析 | 通过查询分析接口的实现,可以定制自己的查询语法规则: 比如: 多个关键词之间的 + - and or关系等 | |
| 并发访问 | 能够支持多用户的使用 |
对于中文来说,全文索引首先还要解决一个语言分析的问题,对于英文来说,语句中单词之间是天然通过空格分开的,但亚洲语言的中日韩文语句中的字是一个字挨一个,所有,首先要把语句中按“词”进行索引的话,这个词如何切分出来就是一个很大的问题。
首先,肯定不能用单个字符作(si-gram)为索引单元,否则查“上海”时,不能让含有“海上”也匹配。
但一句话:“北京天安门”,计算机如何按照中文的语言习惯进行切分呢?
“北京 天安门” 还是“北 京 天安门”?让计算机能够按照语言习惯进行切分,往往需要机器有一个比较丰富的词库才能够比较准确的识别出语句中的单词。
另外一个解决的办法是采用自动切分算法:将单词按照2元语法(bigram)方式切分出来,比如:
"北京天安门" ==> "北京 京天 天安 安门"。
这样,在查询的时候,无论是查询"北京" 还是查询"天安门",将查询词组按同样的规则进行切分:"北京","天安安门",多个关键词之间按与"and"的关系组合,同样能够正确地映射到相应的索引中。这种方式对于其他亚洲语言:韩文,日文都是通用的。
基于自动切分的最大优点是没有词表维护成本,实现简单,缺点是索引效率低,但对于中小型应用来说,基于2元语法的切分还是够用的。基于2元切分后的索引一般大小和源文件差不多,而对于英文,索引文件一般只有原文件的30%-40%不同,
| 自动切分 | 词表切分 | |
| 实现 | 实现非常简单 | 实现复杂 |
| 查询 | 增加了查询分析的复杂程度, | 适于实现比较复杂的查询语法规则 |
| 存储效率 | 索引冗余大,索引几乎和原文一样大 | 索引效率高,为原文大小的30%左右 |
| 维护成本 | 无词表维护成本 | 词表维护成本非常高:中日韩等语言需要分别维护。 还需要包括词频统计等内容 |
| 适用领域 | 嵌入式系统:运行环境资源有限 分布式系统:无词表同步问题 多语言环境:无词表维护成本 | 对查询和存储效率要求高的专业搜索引擎 |
目前比较大的搜索引擎的语言分析算法一般是基于以上2个机制的结合。关于中文的语言分析算法,大家可以在Google查关键词"wordsegment search"能找到更多相关的资料。
下载:http://jakarta.apache.org/lucene/
注意:Lucene中的一些比较复杂的词法分析是用JavaCC生成的(JavaCC:JavaCompilerCompiler,纯Java的词法分析生成器),所以如果从源代码编译或需要修改其中的QueryParser、定制自己的词法分析器,还需要从https://javacc.dev.java.net/下载javacc。
lucene的组成结构:对于外部应用来说索引模块(index)和检索模块(search)是主要的外部应用入口
| org.apache.Lucene.search/ | 搜索入口 |
| org.apache.Lucene.index/ | 索引入口 |
| org.apache.Lucene.analysis/ | 语言分析器 |
| org.apache.Lucene.queryParser/ | 查询分析器 |
| org.apache.Lucene.document/ | 存储结构 |
| org.apache.Lucene.store/ | 底层IO/存储结构 |
| org.apache.Lucene.util/ | 一些公用的数据结构 |
简单的例子演示一下Lucene的使用方法:
索引过程:从命令行读取文件名(多个),将文件分路径(path字段)和内容(body字段)2个字段进行存储,并对内容进行全文索引:索引的单位是 Document对象,每个Document对象包含多个字段Field对象,针对不同的字段属性和数据输出的需求,对字段还可以选择不同的索引/存储字 段规则,列表如下:| 方法 | 切词 | 索引 | 存储 | 用途 |
|---|---|---|---|---|
| Field.Text(String name, String value) | Yes | Yes | Yes | 切分词索引并存储,比如:标题,内容字段 |
| Field.Text(String name, Reader value) | Yes | Yes | No | 切分词索引不存储,比如:META信息, 不用于返回显示,但需要进行检索内容 |
| Field.Keyword(String name, String value) | No | Yes | Yes | 不切分索引并存储,比如:日期字段 |
| Field.UnIndexed(String name, String value) | No | No | Yes | 不索引,只存储,比如:文件路径 |
| Field.UnStored(String name, String value) | Yes | Yes | No | 只全文索引,不存储 |
public class IndexFiles {
//使用方法:: IndexFiles [索引输出目录] [索引的文件列表] ...
public static void main(String[] args) throws Exception {
String indexPath = args[0];
IndexWriter writer;
//用指定的语言分析器构造一个新的写索引器(第3个参数表示是否为追加索引)
writer = new IndexWriter(indexPath, new SimpleAnalyzer(), false);
for (int i=1; i
InputStream is = new FileInputStream(args[i]);
//构造包含2个字段Field的Document对象
//一个是路径path字段,不索引,只存储
//一个是内容body字段,进行全文索引,并存储
Document doc = new Document();
doc.add(Field.UnIndexed("path", args[i]));
doc.add(Field.Text("body", (Reader) new InputStreamReader(is)));
//将文档写入索引
writer.addDocument(doc);
is.close();
};
//关闭写索引器
writer.close();
}
}
索引过程中可以看到:
- 语言分析器提供了抽象的接口,因此语言分析(Analyser)是可以定制的,虽然lucene缺省提供了2个比较通用的分析器 SimpleAnalyser和StandardAnalyser,这2个分析器缺省都不支持中文,所以要加入对中文语言的切分规则,需要修改这2个分析 器。
- Lucene并没有规定数据源的格式,而只提供了一个通用的结构(Document对象)来接受索引的输入,因此输入的数据源可以是:数据库,WORD文档,PDF文档,HTML文档……只要能够设计相应的解析转换器将数据源构造成成Docuement对象即可进行索引。
- 对于大批量的数据索引,还可以通过调整IndexerWrite的文件合并频率属性(mergeFactor)来提高批量索引的效率。
检索过程和结果显示:
搜索结果返回的是Hits对象,可以通过它再访问Document==>Field中的内容。
假设根据body字段进行全文检索,可以将查询结果的path字段和相应查询的匹配度(score)打印出来,
public class Search {
public static void main(String[] args) throws Exception {
String indexPath = args[0], queryString = args[1];
//指向索引目录的搜索器
Searcher searcher = new IndexSearcher(indexPath);
//查询解析器:使用和索引同样的语言分析器
Query query = QueryParser.parse(queryString, "body",
new SimpleAnalyzer());
//搜索结果使用Hits存储
Hits hits = searcher.search(query);
//通过hits可以访问到相应字段的数据和查询的匹配度
for (int i=0; i
hits.score(i));
};
}
} 在整个检索过程中,语言分析器,查询分析器,甚至搜索器(Searcher)都是提供了抽象的接口,可以根据需要进行定制。 简化的查询分析器
个人感觉lucene成为JAKARTA项目后,画在了太多的时间用于调试日趋复杂QueryParser,而其中大部分是大多数用户并不很熟悉的,目前LUCENE支持的语法:
Query ::= ( Clause )*
Clause ::= ["+", "-"] [
中间的逻辑包括:and or + - &&||等符号,而且还有"短语查询"和针对西文的前缀/模糊查询等,个人感觉对于一般应用来说,这些功能有一些华而不实,其实能够实现 目前类似于Google的查询语句分析功能其实对于大多数用户来说已经够了。所以,Lucene早期版本的QueryParser仍是比较好的选择。
添加修改删除指定记录(Document)
Lucene提供了索引的扩展机制,因此索引的动态扩展应该是没有问题的,而指定记录的修改也似乎只能通过记录的删除,然后重新加入实现。如何删除 指定的记录呢?删除的方法也很简单,只是需要在索引时根据数据源中的记录ID专门另建索引,然后利用IndexReader.delete (Termterm)方法通过这个记录ID删除相应的Document。
根据某个字段值的排序功能
lucene缺省是按照自己的相关度算法(score)进行结果排序的,但能够根据其他字段进行结果排序是一个在LUCENE的开发邮件列表中经常 提到的问题,很多原先基于数据库应用都需要除了基于匹配度(score)以外的排序功能。而从全文检索的原理我们可以了解到,任何不基于索引的搜索过程效 率都会导致效率非常的低,如果基于其他字段的排序需要在搜索过程中访问存储字段,速度回大大降低,因此非常是不可取的。
但这里也有一个折中的解决方法:在搜索过程中能够影响排序结果的只有索引中已经存储的docID和score这2个参数,所以,基于score以外 的排序,其实可以通过将数据源预先排好序,然后根据docID进行排序来实现。这样就避免了在LUCENE搜索结果外对结果再次进行排序和在搜索过程中访 问不在索引中的某个字段值。
这里需要修改的是IndexSearcher中的HitCollector过程:
...
scorer.score(new HitCollector() {
private float minScore = 0.0f;
public final void collect(int doc, float score) {
if (score > 0.0f && // ignore zeroed buckets
(bits==null || bits.get(doc))) { // skip docs not in bits
totalHits[0]++;
if (score >= minScore) {
/* 原先:Lucene将docID和相应的匹配度score例入结果命中列表中:
* hq.put(new ScoreDoc(doc, score)); // update hit queue
* 如果用doc 或 1/doc 代替 score,就实现了根据docID顺排或逆排
* 假设数据源索引时已经按照某个字段排好了序,而结果根据docID排序也就实现了
* 针对某个字段的排序,甚至可以实现更复杂的score和docID的拟合。
*/
hq.put(new ScoreDoc(doc, (float) 1/doc ));
if (hq.size() > nDocs) { // if hit queue overfull
hq.pop(); // remove lowest in hit queue
minScore = ((ScoreDoc)hq.top()).score; // reset minScore
}
}
}
}
}, reader.maxDoc());
更通用的输入输出接口
虽然lucene没有定义一个确定的输入文档格式,但越来越多的人想到使用一个标准的中间格式作为Lucene的数据导入接口,然后其他数据,比如 PDF只需要通过解析器转换成标准的中间格式就可以进行数据索引了。这个中间格式主要以XML为主,类似实现已经不下4,5个:
数据源: WORD PDF HTML DB other
\ | | | /
XML中间格式
|
Lucene INDEX
目前还没有针对MSWord文档的解析器,因为Word文档和基于ASCII的RTF文档不同,需要使用COM对象机制解析。这个是我在Google上查的相关资料:http://www.intrinsyc.com/products/enterprise_applications.asp
另外一个办法就是把Word文档转换成text:http://www.winfield.demon.nl/index.html
索引过程优化
索引一般分2种情况,一种是小批量的索引扩展,一种是大批量的索引重建。在索引过程中,并不是每次新的DOC加入进去索引都重新进行一次索引文件的写入操作(文件I/O是一件非常消耗资源的事情)。
Lucene先在内存中进行索引操作,并根据一定的批量进行文件的写入。这个批次的间隔越大,文件的写入次数越少,但占用内存会很多。反之占用内存 少,但文件IO操作频繁,索引速度会很慢。在IndexWriter中有一个MERGE_FACTOR参数可以帮助你在构造索引器后根据应用环境的情况充 分利用内存减少文件的操作。根据我的使用经验:缺省Indexer是每20条记录索引后写入一次,每将MERGE_FACTOR增加50倍,索引速度可以 提高1倍左右。
搜索过程优化
lucene支持内存索引:这样的搜索比基于文件的I/O有数量级的速度提升。
http://www.onjava.com/lpt/a/3273
而尽可能减少IndexSearcher的创建和对搜索结果的前台的缓存也是必要的。
Lucene面向全文检索的优化在于首次索引检索后,并不把所有的记录(Document)具体内容读取出来,而起只将所有结果中匹配度最高的头 100条结果(TopDocs)的ID放到结果集缓存中并返回,这里可以比较一下数据库检索:如果是一个10,000条的数据库检索结果集,数据库是一定 要把所有记录内容都取得以后再开始返回给应用结果集的。所以即使检索匹配总数很多,Lucene的结果集占用的内存空间也不会很多。对于一般的模糊检索应 用是用不到这么多的结果的,头100条已经可以满足90%以上的检索需求。
如果首批缓存结果数用完后还要读取更后面的结果时Searcher会再次检索并生成一个上次的搜索缓存数大1倍的缓存,并再重新向后抓取。所以如果 构造一个Searcher去查1-120条结果,Searcher其实是进行了2次搜索过程:头100条取完后,缓存结果用完,Searcher重新检索 再构造一个200条的结果缓存,依此类推,400条缓存,800条缓存。由于每次Searcher对象消失后,这些缓存也访问那不到了,你有可能想将结果 记录缓存下来,缓存数尽量保证在100以下以充分利用首次的结果缓存,不让Lucene浪费多次检索,而且可以分级进行结果缓存。
Lucene的另外一个特点是在收集结果的过程中将匹配度低的结果自动过滤掉了。这也是和数据库应用需要将搜索的结果全部返回不同之处。
- 支持中文的Tokenizer:这里有2个版本,一个是通过JavaCC生成的,对CJK部分按一个字符一个TOKEN索引,另外一个是从SimpleTokenizer改写的,对英文支持数字和字母TOKEN,对中文按迭代索引。
- 基于XML数据源的索引器:XMLIndexer,因此所有数据源只要能够按照DTD转换成指定的XML,就可以用XMLIndxer进行索引了。
- 根 据某个字段排序:按记录索引顺序排序结果的搜索器:IndexOrderSearcher,因此如果需要让搜索结果根据某个字段排序,可以让数据源先按某 个字段排好序(比如:PriceField),这样索引后,然后在利用这个按记录的ID顺序检索的搜索器,结果就是相当于是那个字段排序的结果了。
Luene的确是一个面对对象设计的典范
- 所有的问题都通过一个额外抽象层来方便以后的扩展和重用:你可以通过重新实现来达到自己的目的,而对其他模块而不需要;
- 简单的应用入口Searcher, Indexer,并调用底层一系列组件协同的完成搜索任务;
- 所 有的对象的任务都非常专一:比如搜索过程:QueryParser分析将查询语句转换成一系列的精确查询的组合(Query),通过底层的索引读取结构 IndexReader进行索引的读取,并用相应的打分器给搜索结果进行打分/排序等。所有的功能模块原子化程度非常高,因此可以通过重新实现而不需要修 改其他模块。
- 除了灵活的应用接口设计,Lucene还提供了一些适合大多数应用的语言分析器实现(SimpleAnalyser,StandardAnalyser),这也是新用户能够很快上手的重要原因之一。
这些优点都是非常值得在以后的开发中学习借鉴的。作为一个通用工具包,Lunece的确给予了需要将全文检索功能嵌入到应用中的开发者很多的便利。
此外,通过对Lucene的学习和使用,我也更深刻地理解了为什么很多数据库优化设计中要求,比如:
- 尽可能对字段进行索引来提高查询速度,但过多的索引会对数据库表的更新操作变慢,而对结果过多的排序条件,实际上往往也是性能的杀手之一。
- 很多商业数据库对大批量的数据插入操作会提供一些优化参数,这个作用和索引器的merge_factor的作用是类似的,
- 20%/80%原则:查的结果多并不等于质量好,尤其对于返回结果集很大,如何优化这头几十条结果的质量往往才是最重要的。
- 尽可能让应用从数据库中获得比较小的结果集,因为即使对于大型数据库,对结果集的随机访问也是一个非常消耗资源的操作。
参考资料:
Apache: Lucene Project
http://jakarta.apache.org/lucene/
Lucene开发/用户邮件列表归档
Lucene-dev@jakarta.apache.org
Lucene-user@jakarta.apache.org
The Lucene search engine: Powerful, flexible, and free
http://www.javaworld.com/javaworld/jw-09-2000/jw-0915-Lucene_p.html
Lucene Tutorial
http://www.darksleep.com/puff/lucene/lucene.html
Notes on distributed searching with Lucene
http://home.clara.net/markharwood/lucene/
中文语言的切分词
http://www.google.com/search?sourceid=navclient&hl=zh-CN&q=chinese+word+segment
搜索引擎工具介绍
http://searchtools.com/
Lucene作者Cutting的几篇论文和专利
http://lucene.sourceforge.net/publications.html
Lucene的.NET实现:dotLucene
http://sourceforge.net/projects/dotlucene/
Lucene作者Cutting的另外一个项目:基于Java的搜索引擎Nutch
http://www.nutch.org/ http://sourceforge.net/projects/nutch/
关于基于词表和N-Gram的切分词比较
http://china.nikkeibp.co.jp/cgi-bin/china/news/int/int200302100112.html
2005-01-08 Cutting在Pisa大学做的关于Lucene的讲座:非常详细的Lucene架构解说
特别感谢:
前网易CTO许良杰(Jack Xu)给我的指导:是您将我带入了搜索引擎这个行业。
Labels: Lucene, search engine
Tuesday, June 05, 2007
百度西顾 惊了谷歌和欧陆
 百度能否在谷歌跟前抢滩登陆?
百度能否在谷歌跟前抢滩登陆?在百度的搜索引擎里搜索中国国骂的缩写“SB”,第一个跳出来的结果就是“谷歌”,网友戏言两者积怨之深可见一斑。而随着欧洲媒体竞相报道百度首席财务官 王湛生将在本月晚些时候的投资者大会上公布新的欧洲市场拓展计划,百度和谷歌的较量从中国国内市场打到欧洲市场。德国之声中文网报道如下:
百度进军欧洲市场的消息最先是由英国的 星期日电讯报(Sunday Telegraph)披露的,随即在市场中掀起了轩然大波。周日电讯报称,王湛生将在6月19日于伦敦的投资者大会上公布百度在欧洲的战略方案,不过该报 并没有明确报道百度的欧陆拓展计划,也没有公布具体的时间表,只是建议百度以特定的内容来吸引年轻的互联网用户。
不过很快百度高层就通过上海证券报辟谣说:“这是百度高层在纳斯达克向投资者介绍业务时,外电媒体误听导致的传闻。”
那么,百度究竟是否有心欧洲乃至国际市场呢?
百度“摆渡”到欧陆?
从国际市场来看,谷歌是当之无愧的业界老大,全 球每个月6.35亿的搜索页,有73%都是通过谷歌完成的;但是在中国市场,业界老大却不得不乖乖的向地头蛇百度弯腰,后者在中国每个月的使用者为 5900万,比谷歌整整多出了1500万,这个优势还有不断扩大的趋势。所谓的“攘外必先安内”,中国本土市场,百度已经遥遥领先。
于是,百度开始了国际化之路。今年早些时候,百度宣布进军日本市场,这也是其在中国市场之外的首次拓展,尽管谷歌和雅虎占据了日本搜索市场的90%,但是百度还是义无反顾的投身其中。百度总裁李彦宏更是公开表示不怕自己在中国的“手下败将”谷歌和雅虎。
既然有东进日本的先例,当然不能排除百度西征欧陆的野心。况且李彦宏早就放出话来:“不指望国际化进程能马上带来收益,但是真正的跨国公司,他们的收入来源(按照地域来讲)都是多元化的。”
除了进军日本市场之外,百度在国际化方面另有大 得举措,今年1月16日,百代唱片(EMI Music)和百度宣布达成全面战略合作,共同为中国用户提供华语音乐在线服务。根据协议,百代授权百度使用其所有华语歌曲,供网民在百度MP3搜索上免 费试听,而百代和百度将通过广告商的赞助进行分成。百代此次和百度的合作仅限于中文歌曲的在线试听,并不包括英文歌曲,而且合作方式并不包括下载。
百度与百代的合作是相当成功的,这次合作为百度带来了超过30%的流量。因此,不排除百度用同样的方式来开拓欧洲市场,这也与星期日电讯报所说的“以特定的内容来吸引年轻的互联网用户”是不谋而合的。
从CNNIC最新提供的数据来看,谷歌在搜索相 关性、结果公正性、公司文化和企业精神、技术创新性和总体评价方面均优于百度,仅仅在接入速度和服务器稳定性两个指标落后于百度,但是正是这两个指标的差 异,使得谷歌在中国与百度的交手中处在了下风。在国际市场的较量中,百度能否击败强大的谷歌还很难讲,不过业内人士也已经指出,从技术角度,百度进军欧洲 市场并没有什么障碍,倘若百度将他们在中国大陆市场绞杀三巨头雅虎、谷歌和MSN的手段使出来,不见得一定会在欧洲市场的较量中落马。
百度国际化,谷歌本土化
百度和谷歌同样以搜索引擎为主要业务对象,就某种意义上而言,谷歌既是百度的竞争对手,也应该是百度值得效仿的对象。
在相当长的一段时间内,谷歌一直试图在搜索引擎 方面击败雅虎独占鳌头。目前来看,他们的目的已经达到了。仅仅就搜索引擎技术而言,谷歌已经全面超越了雅虎。雅虎主管个性化主页部门的副总裁塔班·巴特 (Tapan Bhat)6月4日在“下一代互联网大会”上的讲话或许标志着雅虎已经间接承认输给谷歌的事实:“搜索已经成为了历史,个性化才是互联网的未来。我们并非 承认失败,搜索仍然发挥着重要的作用,但我们认为应当对搜索加以改进,使之更为有用。”
对巴特的讲话,硅谷专家舒尔茨认为:“他们已经意识到无法再在搜索引擎方面与谷歌展开较量。”而风险投资公司的经理克拉维尔在接受时代在线采访时也一针见血的指出:“雅虎的问题在于他们想为所有的人做所有的事情,但是结果他们没有哪件事情能做得非常好。”
相对于雅虎的博而不精,谷歌始终专注于搜索引擎 市场,他们知道,要想抵御来自雅虎和微软的强势入侵,就必须降低让用户失望的频度。为此谷歌已经将搜索技术逐渐提升到了“给我输入的东西”转变为“给我想 要的东西”,这种在技术上的不断革新,也正是谷歌成功的关键,也是谷歌能够赶超雅虎的根本原因。
或许谷歌赶超雅虎的过程,也正是百度在赶超谷歌 的时候所需要效法的。当然,百度在加快国际化步伐的同时,也应该意识到,谷歌正在加快在中国大陆的本土化过程,谷歌中国三驾马车中两人周韶宁和王怀南相继 离职,也说明了谷歌在中国收复失地的决心和勇气。一旦在中国市场的较量中输给了谷歌,百度的欧陆扩展计划也就成了一纸空言,毕竟任何跨国公司,都是以本土 市场为依托的。
虽然贵为世界第五大搜索引擎,但是百度想成功的 在欧洲开辟市场,难度还是空前的。仅仅就域名来看,www.baidu.eu已经被一家荷兰互联网服务公司抢注,该公司的网站上同时注明“Baidu 是注册商标,版权所有”。百度不来欧洲便罢,来了,恐怕先就有一场官司在恭候着他们。
Labels: Baidu, search engine
Sunday, April 08, 2007
击败Google的赛跑
来源:译言
原作者: Alex Iskold | 译者: 凉拌傻瓜 ![]() | 发表时间:2007-03-20
| 发表时间:2007-03-20

在纽约时报2007年1月1日的一篇文章中,记者Miguel Helft 写了一篇有关硅谷中正在进行的击败Google的赛跑的报道。当然,搜索的未来最近已经被谈得很多了。去年Read/WriteWeb(译者注:ReadWriteWeb是Richard MacManus所整理的博客)有相当数量的文章关于这个话题,包括Emre的搜索2.0以及我有关垂直搜索的一篇文章。我们也介绍了很多搜索的网站,包括 Retrevo, Hakia, Quintura, Pluggd, Microsoft Live Search, Snap 和 ChaCha。由于我们始终紧跟着这场战役,对于《纽约时报》的这篇报道我们也异常兴奋,这意味着搜索已经火热到,值得有技术理解的主流受众关注的程度了。
Miguel Helft完成了这篇文章的主要内容。他写到,数目巨大的风险资本流入了搜索市场——不是一定为了击败Google,而可能是为了从巨大的广告市场分得一杯羹。然而Helft认为,尽管有很多公司尝试着想要追赶,但他不确信他们是否能追得上。虽然Google不像微软一样是一个垄断企业,但要超越他仍然看上去不那么现实。
显然,我们对Google的统治地位都有相同的感觉——但这是为什么呢?为了能够更好的理解,我们需要来划分一下Google的竞争对手及他们的方法。在这篇文章中,我们会用Emre的分类来理解,为什么我们都直觉地认为Google会继续保持他搜索之王的地位。
竞争技术的分类
对一个新公司来说,有两个非常经典的商业案例:走更好之路或者更便宜之路。在搜索市场的案例中,更便宜是行不通的。因此,目前搜索市场上的这些企业是在以不同程度的“更好”来竞争。在他的文章中,Emre描述了超越Google的三种主要方式。
l 更好的技术——搜索结果有更好的质量和相关性
l 更好的UI设计——搜索结果以一种更好的方式来呈现
l 垂直/语意搜索——更好技术和更好UI的结合
更好的技术
Google基于Pagerank基础的自动算法是一个现象。想要击败Google的竞争者们正在部署两个完全不同的策略:1)自然语言处理/人工智能技术和2)人的力量。
在人工智能阵营中,Hakia和Powerset正在建立通过更好的理解搜索者意图的技术来提供更好的搜索结果。这两个公司在近期都受到了媒体的大量关注,并且最近我们在这里也回顾过Hakia。虽然理解自然语言的好处是非常明显的,但是它在结果质量上能有多大提升还并不明朗。
从我们目前所能看到的来说,很难去想象这些公司如何来击败Google。首先,Google内部也已经通过了使用自然语言来处理查询,因此这并不是一个有竞争力的差异。他们必须做到实际的结果要大大的好于Google,但是现在这让我们难以想象。也许能够做到好一点,但是要非常不同?很难做到。
人肉搜索(people powered search,指依靠网络中人的力量进行搜索,译者注)是很有意思的,因为它能带来计算机最缺少的东西——常识。del.icio.us 通常并不被当作一个搜索引擎,但它却可能是现实中使用人的力量的最好例子。Del.icio.us的优秀之处在于它给我们带来了很多高质量的、经过过滤的结果。但它的缺点在于,这些结果仅局限于大多数人认为流行的东西。也许有人会说这就是这个网站的本意,但在某些情况下它也会成为一种局限。
另一个问题是,del.icio.us到目前为止只被技术行业的人所使用,因此非技术领域(比如医药领域)的结果并不理想。Chacha使用了一种不同的方法,它有人能够来帮你寻找东西。这是个非常有趣的想法,然而我们在十二月的回顾中也已经指出了一些问题——包括每月要支付的高昂费用(需要支付给搜索向导)以及潜在的规模拓展性问题。虽然类似于del.icio.us这样的方法要优于静态的网页目录,不过看上去人肉搜索要想击败搜索算法是很困难的事情。Google算法的速度和完备性是人肉搜索尤其无法企及的。
更好的UI

Google的座右铭是简洁。这一思想贯穿他们整个产品线,并且受到公司严格的监管。这就是为什么很多竞争对手,想通过在UI上展现更好的搜索结果来和Google竞争。
Snap和微软图片搜索通过展示预览来 增加用户体验。预览非常有趣而且有用。我尤其喜欢微软图片搜索的用户界面,它在图片搜索的界面表现方面有很大的提高。不幸的是,这两种技术都必须改进他们 结果的相关性甚至质量。另外,在图片上有效的,并不一定在搜索结果也有效——如果单纯是由于预览,还是很难决定它是否值得一用。
下面我们来看一下聚类网站,他们尝试去做垂直搜索引擎所做的事情——不过是通过公告牌和使用完整结果。Clusty让人印象深刻,因为它在不改变我们搜索结果习惯的同时增加了许多价值。和搜索结果一样,聚类的标签使用户们能更加细化他们的查询——通常不超过两步就能得到答案。
这个类别中的第二个搜索引擎是Searchmash,它为Google所有并且明显是他们的游乐场。Searchmash所引人注目的是它修行者一般的外表——如此典型的Google风格,它创造了一个更加丰富的方式来看搜索的结果。它运用了AJAX技术和只展示搜索结果标题的模式。我发现这种模式令人吃惊的有用。在结果页面还有一些按钮把结果分成不同的垂直领域,如博客、新闻和图片,这些都非常直截了当。这两个网站(Clusty和Searchmash)看上去都非常有用,而且能够被主流所接受。
在最后一个更好UI的次类别里,我们发现Quintura和Kartoo 都把创新的视觉技术应用到了搜索中。Quintura设置了一个类似于标签——云的图像来展示搜索结果的聚类。在这方面,这个主意和Clusty非常像——只是实现的方式不同。Kartoo使用了像分子运动图一样图像来精确地表现相同的聚类划分。以我来看,这两种方法的问题都在于它们太复杂了,使它们难于被主流所接受。即使我在图像视觉方面有一些基础,我并不觉得它们中的哪一个明显和直观。在这个具体表现上,视觉搜索并不能被广泛接受。
很多UI的改进都非常巧妙和有趣,但是没有一个有能力击败Google。主要原因是因为要复制它们很简单。当然在法律上不可能有完全一样的克隆,但在这种情况下足够相似就意味着足够好。没有一项技术对Google来说有进入壁垒,因此即使它们中有的能够获得足够的市场份额,Google也能简单地进行升级。注意Google正在耍玩的Searchmash.com已经对目前的垂直搜索引擎提供商产生了影响。
垂直搜索

有关垂直搜索已经有了很多文章和一个好的理由。这些网站是想通过更好的技术、更好的UI以及专注于某一特定的垂直领域来超越Google。很多网站由于用户需求和盈利的机会,选择了博客、分类、电子、健康、工作和旅游搜索引擎。
想一下这个简单的例子。如果你想找有关Web2.0的博客文章,你会使用普通的Google呢还是用Google博客搜索?很明显Google自己也认识到了专门化搜索的实用性,即使没有进入每一个垂直领域,至少专注于类似博客和音乐这类方面。毫无疑问,垂直搜索是有意义的并将一直如此。关键问题是,垂直搜索引擎能夺走多少搜索市场份额呢?
事实上,可能会很多。我们在这里提到的所有领域都是受到广告主们追捧,已经盈利或者即将盈利的。因此确切地说这意味着什么呢?既然Google已经进入了博客和音乐的垂直领域,那它向其他领域进军只是时间的问题。这对目前的网站来说意味着很多麻烦(想一想Google博客搜索超过Technorati),取决于这将在多快时间内发生。只有那些已经建立了很强品牌的才能够生存下来(像Technorati)。
结论
因此总的来说,即使这个市场相当活跃,在可以预见的将来Google仍然将维持着搜索之王的地位。各种各样的方法在获得市场份额方面会获得不同程度的成功,但是要想在市场上取得可观的成绩,需要时间、无可挑剔的执行、巨额的市场营销预算,当然还需要更好的技术。这并不是很多琐碎小事的集合。
假定前三项是难点,但是可实现的,我们仍然需要来理解更好的技术的含义。我的想法是能够更快地提供相关的结果。从这个观点来看,另一个有希望的竞争者(Emre提到过)就是个性化搜索。在这个技术的基础上,搜索结果就不是按照Pagerank来组织,而是依据你个人的兴趣。垂直搜索和个性化搜索的组合有希望提供比Google更好的结果,也许还有机会。但是,正如我们对其他网站所指出的,Google也并没有一直在睡觉。
本文由译言网的凉拌傻瓜翻译。作者的其他文章有:
Labels: search engine
![]()