Wednesday, May 27, 2009
一个 Web 设计师一天的程序生涯

http://www.cnbeta.com/articles/85332.htm
感谢COMSHARP CMS的投递
新闻来源:CSS Tricks
一个 Web 设计师每天要使用多少程序?本文的原文作者 Chris Coyier 是一位住在美国 Portland 的 Web 设计师,他的日程排得很满,从早上6点一直工作到晚上10点,以下是他每天使用的程序清单,当然他并非按次序使用这些程序,这些程序在他的工作中是交叉使用的。
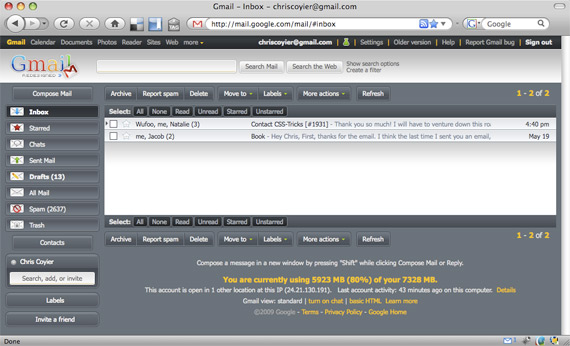
我离不开 Gmail,它是我的 TO DO list。
6:01am Adium / iChat
作者使用的 IM 工具是 Adium 和 iChat。译者本人青睐 Skype,但国内用 Skype 的不是很普遍,MSN 太难用了,QQ 却只是一味地热闹,但国内用 QQ 是绝对的主流,虽然很厌恶这个工具。
6:10am Are My Sites Up
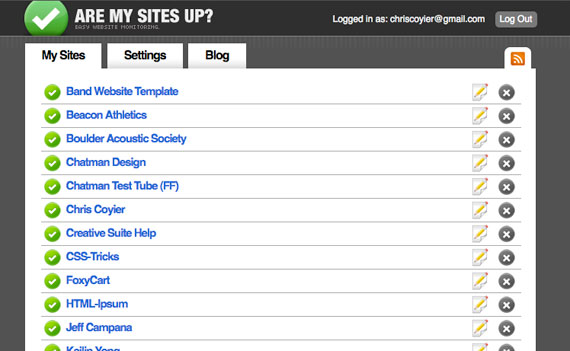
查邮件的时候,顺便从 My Sites Up 看看我的网站和服务器是否有 Down 机?
6:20am Wufoo

收邮件的同时,那些通过 WuFoo 表单程序来的通知也随之到来,作者每天用 WuFoo 设计了大量的表单,WuFoo 设计的表单,可以将反馈信息直接发送到邮件。译者更喜欢 PollDaddy。
6:35am Things
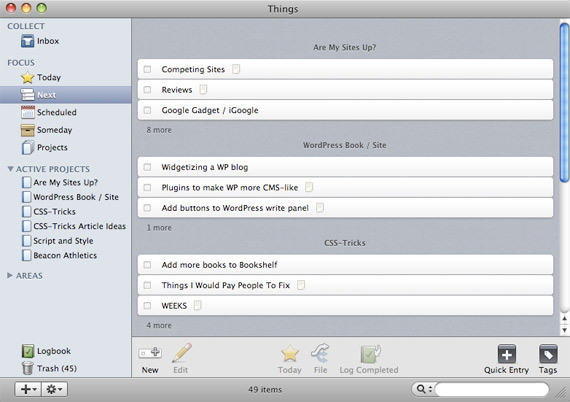
使用 Things 安排工作计划与日程。关于计划和日程安排,译者本人觉得最好用的是记事本,人的大脑有很强的概括能力,你最近要做的事,大脑里有非常准确的轮廓,但细节要靠记事本。
7:10am Coda
做 Web 设计,是不能不使用苹果的,因此作者使用 Coda 做设计编辑工具,当然 Coda 确实很好用。Notepad++ 是译者首选。
7:27am Photoshop

作者拥有全套 Creative Suite,但里面真正好用的是 Photoshop,即时做一些很简单的东西,也用 Photoshop。
8:01am Firefox

作者设计的站点首先在 Firefox 中显示,然后在所有其它浏览器中测试。
9:19am Firebug
Firefox 好用,但用 Safari 也没问题,但 Safari 里面没有 Firebug,很难想象在没有 Firebug 的情形下写 HTML / CSS / JavaScript。
9:50am Skitch
工作中,要和别人分享屏幕,Skitch 是很有趣的工具。
10:07am MailChimp
这个程序帮助我的客户处理邮件列表。有时候,也用 SendLoop。
10:32am Google Reader
我不是机器,需要休息,有时候,休息是远离电脑,有时候是打开 Google Reader 读一读 Web 行业文章。
10:34am iTunes
工作中,一些大量用脑的地方需要安静,一些地方可以一遍听着音乐。译者自己的经验是,如果工作者牵涉到文字,语言的地方,听音乐会分神,而逻辑思维,编程,图形设计这些地方可以开着音乐,当然这个因人而异。
11:40am VMWare Fusion & Windows
我使用 Fusion 是为了在苹果机运行 Windows,而运行 Windows 的唯一目的是运行下面那个程序。
12:37pm IETester
用来测试所有主要的 IE 版本。
1:01pm iPhone Simulator

要检查一个站点是否可以在 iPhone 中正常显示,我使用 iPhone SDk中的这个 iPhone Simulator 模拟器。
1:30pm FontExplorer X Pro
管理我的字体。
1:44pm WordPress
我把自己几乎所有工作和个人站点都转移到了 Wordpress。使用一个统一的发布平台很省事。
2:11pm Microsoft Office
Apple 的 Pages 和 Numbers 很好用,但实际工作中,你避免不了 Office。有时候,需要协同工作的场合,我使用 Google Docs,但还替代不了 Office。
3:05pm FreshBooks
一项工作结束,该收钱的时候,FreshBooks 可以处理这些工作。
4:07pm BuySellAds
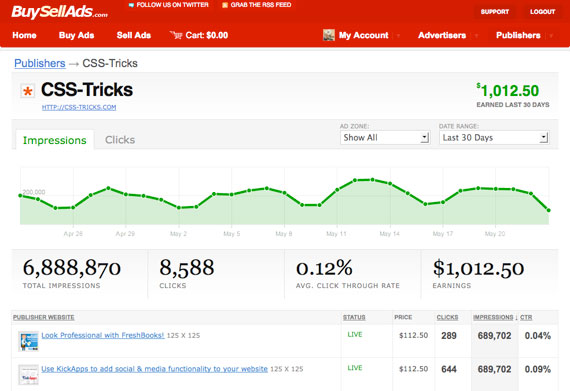
到了晚上,我可以处理自己的项目了,像 CSS-Tricks,这些项目要用到 BuySellAds,来管理广告的部署。
5:30pm iCal
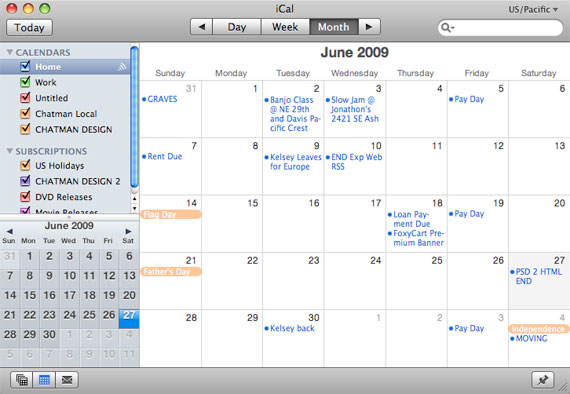
对于那些很遥远的未来的项目,我用 iCal 管理日程,日常的管理就没什么用了。
9:18pm Google Analytics

我曾经对 web 流量分析很着迷,但现在不了, Google Analytics 很好用,有时候也使用 Mint,但更喜欢免费的 Google Analytics。
10:04pm Tweetie

Twitter 的一个客户端。
本文来源:http://css-tricks.com/applications-one-day-in-the-life-of-a-web-designer/
中文翻译来源:COMSHARP CMS 官方网站
除了暴风影音,还有很多影音播放器可以选择
来源: 可能吧
事实证明,在LJ的文章“暴风长老,请收了神通吧!”里,我后补的猜想是不怀好意的,网络瘫痪真的是由暴风影音直接引起的。
在“暴风长老,请收了神通吧!”里,我看到很多朋友都对暴风影音表示不耻,尤其是反感它的广告。事实上这个世界不止有暴风影音这一款免费的播放器,如果你无法忍受暴风影音的广告和后门,你还有很多选择,这篇文章简单介绍4个影音播放器。
这里主要介绍Windows下的播放器,如果你是Linux用户,可以参看10款Linux常用的媒体播放器。
一、4款干净的播放器
1、省力:K-Lite Codec Pack
严格来说,K-Lite Codec Pack并不是一个播放器,虽然完全版的包里携带了一个MPC。K-Lite Codec Pack是一系列的影音编码解码器。
Windows Media Player之所以支持的格式不多其中一个原因是因为它的编码解码器不够多,在安装K-Lite Codec Pack后,Windows Media Player就能播放绝大多数常用的媒体格式了,包括rmvb等。
K-Lite Codec Pack分基本包、标准包、完整包三个安装包,其包含的解码器依次增加,完整包里还包含了Media Player Classic播放器。

K-Lite Codec Pack的好处在于,你无需安装一个新的播放器,Windows自带了Windows Media Player,我们完全不用担心Windows Media Player会做出和暴风影音一样的事情。Windows Media Player+K-Lite Codec Pack已经能满足绝大多数人的需求了。
2、简洁:Media Player Classic
也许有人会记得暴风影音以前可爱简洁的界面,其实那就是它们将开源的Media Player Classic和一些相关解码器打包而成的。
MPC是一款非常简洁的播放器,界面和Win98里的Windows Media Player非常相像,我个人是十分喜欢如此简洁的播放器的。当然,功能上也相对缺乏。
目前我电脑里安装的是Media Player Classic Homecinema,它是在MPC基础上修改而成的绿色软件,在保留MPC的简洁之外,还提供了字幕同步等功能。

如果你是个简洁界面爱好者,推荐使用Media Player Classic Homecinema+K-Lite Codec Pack这样的组合。
3、方便:QQ影音
只要你知道腾讯的模仿史,你就不难理解为什么腾讯会推出媒体播放器。我对腾讯的态度一直是有所保留的,但如果从用户体验上理性分析,腾讯确实有几个产品值得称道,比如QQ邮箱(国内邮箱不值得信任不是QQ邮箱的错)、QQ影音、QQ拼音。
或许有些人看到QQ这2个字母会觉得有点低端而不想使用,实际上QQ影音是值得尝试的。

QQ影音可以说是暴风影音的无广告版,暴风影音之所以留后门,其中一个原因是迫于盈利的压力。而我相信腾讯是无需在QQ影音插播广告的,至少目前来说如此。
QQ影音安装配置都很简便、支持常用的视频格式、硬件加速等,适合于不喜欢折腾的人。
4、强大:KMPlayer
KMPlayer现在是我的主力播放器之一,它将网络上大多数的编码解码器捆绑在安装包里,官方有中文版。
由于捆绑了几乎所有可见的编码解码器,它能播放几乎所有的音视频格式,同时,它的功能十分强大,包括:字幕、视频捕抓、硬件加速、皮肤、快捷键、滤镜……功能强大得难以置信。

KMPlayer功能参数设置截图:

如果你是经常折腾Firefox、Wordpress的人,KMPlayer你应该也会喜欢的,因为它的定制性是足够强大的。
目前KMPlayer已打入国际化市场,但依然保留着无广告、不留后门、免费3大优点,实在是难能可贵的。
二、理解广告,鄙视流氓
我看到很多朋友都谴责暴风影音的广告,认为一款媒体播放器根本没有必要联网、也没有必要插播广告。
没有人是愿意免费给其他人提供优秀的服务的,上面介绍的播放器,之所以免费而且无广告,是因为它们是开源软件或者有其它的收入来源支持。而暴风必须通过暴风影音来盈利。
有些时候,我们总希望得到免费的、优秀的软件,这种付出远远小于得到的态度使得中国的盗版、破解版软件泛滥,而有些人还以使用盗版为荣、认为其他人必须为自己付出,这包括一些使用盗版windows还引以为荣的人、无耻抄袭博客文章的人。
对于暴风影音,我认为应该持两种态度:
1、理解广告
在恶劣的中文互联网环境里,一款共享软件要生存并不容易,暴风的职员要吃饭,他们不可能免费为大众服务。
我知道广告有时是很烦人的,但我始终不使用Firefox屏蔽广告扩展,因为广告对于一个网站、尤其是内容型网站来说是十分重要的。
软件也是如此,一款免费软件,我们不要要求太多,不要抱着不付出只获取的心理。
2、鄙视流氓
一个软件有广告或附加功能是可以理解的,但在不通知用户情况下安装后台程序并开机运行就是流氓行为。暴风影音显然就是这样一个流氓!
安装暴风影音后,它会偷偷地开机运行一个Stormliv.exe,这是为了随时随地地下载广告和获取用户本地的媒体信息。一个媒体播放器实在没有 必要注册为一个服务并开机运行,播放器启动后连接服务器下载广告是可以理解的,但在没有启动播放器的情况下都不断连接服务器获取广告,这是让人反感的。
更让人反感的是,网络大面积瘫痪后暴风公司的态度,他们不但不承认是自身软件的流氓,反倒把自己掩饰成受害者,这种流氓,应该扼杀。
Labels: Windows, 广告, 播放器, 暴风影音, 流氓
互联网抄袭带来什么问题?博客应该如何应对?
来源:

一、现状
你在开玩笑吧?就你个破博客,抄你的文章是看得起你。
这是比流氓软件更流氓的人说的话。
别小看抄袭这事,也不要因为你的博客不够受人重视就放弃你的权利,你的东西始终是你的,除非你放弃拥有。
互联网的侵权是比较难以界定的,一方面没有完善的法律,另一方面由于大多数内容都是免费获得的,因此抄袭者才得以如此猖狂。
我们经常在一些网站看到这样一句话:
本网站的新闻及资料均来自网络,如有侵权请告之我们,我们会在最短时间内删除您的文章或者资料,保护你的权利。
很多网站以为登出这样一句话就没有问题,这是不负责任的表现。
作为一个负责任的网站,在转载之前应该看清原创内容出处使用什么授权协议,如果没有看到协议,需要与作者联系得到内容使用权,这才是一种负责任的表现。
二、抄袭带来的问题:
1、造成信息重复。
2、可能对原创者造成一定程度上的伤害,这些伤害可能包括:
- 原创博客可以被误以为抄袭方,人格遭低估。
- 若搜索引擎无法有效地判断原创,对原创者来说是一个沉重的打击。这是我反感百度的一个原因。
- 原创者可能损失广告费等。
3、抄袭者容易滋生不劳而获思想,这种思想是要不得的。
4、如果原创者由于得不到应有的回报而放弃创作,互联网的优质内容会损失。
5、基于第四点,如果抄袭与创作进入了恶性循环,原创内容将会越来越少,这是相当可怕的。
三、为什么强调原创?
1、我们正处在web2.0时代,每个人都是内容的创造者,百花齐放。
2、原创是互联网发展的动力,很多人对腾讯表示不耻,一方面是因为它的收费方式与文化,另一方面则是它几乎没有创新的应用,都是模仿出来的。
3、原创内容是互联网生物链里的底层粮食。你可以想象一旦没有了原创,这个世界是多么可怕的。

四、抄袭真的会扼杀原创吗?
1、在一定程度上会,但随着法律的健全和网民(尤其是某些门户网站的编辑)的认知的提高,抄袭将会减少。
2、抄袭要扼杀原创不是自身能办到,还需要搜索引擎的配合,为什么这样说?
- 搜索引擎已经成为大多数人的互联网入口
- 如果同样的文章,抄袭者在搜索引擎的排名更高
- 这样的后果是原创者损失了应得的利益
- 于是,原创内容可以随之减少
如果你叫我给百度一点建议,我会说:尊重原创。
五、对于博客文章,最佳的转载方式:
1、我反对全文照抄的转载,即使以链接的形式标明原文地址。
2、最好的转载方式是引用,然后再发表你自己的观点,全文照抄的文章缺乏你的灵魂,博客的灵魂是你。
3、转载前需要查看该博客的授权协议:是否能转载?以什么形式转载是允许的?
4、图片等多媒体文件不要直接复制粘贴,在转载与引用,抄袭与盗链里已经将这个问题阐述地很清楚,这是对流量的剽窃。
六、那么,博客一般可以采用怎样的内容授权协议呢?
1、如果你的博客没有标明使用什么授权协议,那默认就是版权所有,all right reserved.
2、大多数博客都采用CC创作共用里的“署名-非商业用途”协议,也有的加上“禁止演绎”的规定。
七、CC创作共用协议是什么?
上面提到了CC创作共用协议,那么,CC协议是什么呢?
在互联网外,创作内容一般都是All Right Reserved的,由于互联网的特殊性,Creative Commons应运而生。
CC协议(中国大陆2.5版)包括四个要素:
1、署名。
必须以链接形式标明原文来源。
2、禁止演绎。
不能修改原文内容。
3、非商业用途。
不用用于商业用途。比如商业网站、杂志的转载。
4、相同方式分享。
转载者必须继承原创者的授权协议。
这4个要素可以互相配搭,你可以在页面底部看到可能吧的协议”署名-非商业用途“,你也可以使用”署名-禁止演绎-非商业用途“协议。
如果你的博客还没有加上授权协议,建议加上。


{kind=link}
{kind=link}
八、遇到抄袭怎么办?
一般来说,个人博客遇到文章被不遵循既定协议的抄袭可以采用以下方式解决:
1、直接和抄袭方联系。
告诉抄袭方你博客所采用的CC协议类型,要求其删除或以链接形式标明原文,又或者非商业使用。一般来说,抄袭方都会尊重你的要求,它也不想惹麻烦。
2、如果抄袭方不进行修改,可以请求Google协助:
为什么向Google投诉?
(1)一旦投诉成功,被投诉的网站的Adsense可能被停止投放。要知道,对于很多网站来说,Adsense是最大的收入来源。
(2)如果某网站被多次投诉但没有改善,Google可能会将这个网站从索引库里删除,对于一个内容网站来说,这是一个很大的损失。
向Google投诉的途径:
(1)书面传真侵权投诉到Google,具体可以参考这里。
(2)发送email到adsense-zhs@google.com,告知侵权情况。
觉得这是在开玩笑?不,David Yin去年成功地进行了投诉。
3、如果有必要,诉诸于法律。
九、抄袭不一定是恶意的,有时你可以用下面的理由原谅他们:
1、有时可以得到更多的外链。
2、可能这次对方忘记了加链接。
3、抄袭者刚刚接触互联网,对CC协议不了解。
4、只要你坚持高质量的创作,你最终会得到认可。
十、最后,给抄袭者的一些忠告:
1、放弃抄袭,即使是抄,也要有道德地转载,使用上面所说的最佳转载方式。
2、门户网站编辑们,这篇文章的主角就是你们,作为领先的互联网人员,如果连基本的道德修养和版权常识都没有,这是非常可悲的。
3、以链接的形式标明原文地址对网站流量不会造成太大的损失,反而显出一种负责任的态度,更受人尊重。
4、不要以为抄袭是小事,番茄花园也没有想到出事出得这么突然,这种事,责任没有你想象的那么轻松。
转载与引用,抄袭与盗链
来源:
标题中的四个关键词,对于做网站做博客的人来说,再也熟悉不过了。这四个关键词牵动着利益和道德的问题,利益和道德从来都是一对难以调和的矛盾,但要找到平衡点,也不是不可能的事。
转载,是一种信息的全部转移,是以链接标明原作者的信息把原作者的创作内容进行复制。这对双方都有利-转载者和原创者,他们都把想和别人分享的信息分享出去-以有礼貌的方式。
引用,和转载不同的,这种信息转移的方式是局部的,并不是所有信息,而是引用者想要认可或想传达原创者的部分信息,当然,必定以链接的形式标明信息摘录的地方。这样的转移方式对双方也是有利的。
转载和引用都应该遵循CC创作共用协议,虽然这个协议是民间协定的,但作为一个道德的范畴,每个人都应该了解和遵循。
抄袭,顾名思义,明目张胆地把别人的原创信息转移而标榜着原创的旗号。在中国的互联网,抄袭已经成为一种习惯,一种生存方式,你可以看看各论坛 BBS里有多少信息是抄袭的,没有原文标示;你可以看看各大门户里的新闻有多少是拿了别人的信息连一个反向链接也不给人家,要么写着原创,要么以文本形式 标明作者,要么写着来源网络;你可以搜索一下你的博客里的文章,看互联网上有多少同样的文章但不是来自你的博客。
35个导致你的博客冷清的理由在Google里搜索会出现5万多个结果,很多都没有标明是来自可能吧的,所有可能吧的结果不能排到第一位。
抄袭者没有道德,只顾个人利益,他们可能从来没有想过如果自己辛苦写好的文章被别人抄袭还标榜这原创时的感受。抄袭者把精彩的文章抄袭后不但标榜原 创,还在页面投放广告。试想一下,不需要脑力劳动坐者等别人的成果,等着收广告费,这事多能赚钱啊!很多网站就是建立在抄袭的基础上,没有抄袭,他们会死 去。
有些抄袭者是无意的,他们把文章整篇复制下来就完事了,根本不知道要标明原作者。他们不知道需要那样做,这样的人大有人在。
盗链,和转载,引用,抄袭是分不开的。即使我认为转载引用是好的,但当中不免会伴有盗链的事情发生。所谓盗链问题,其实就是流量问题。在转载,引 用,抄袭中,如果是直接复制原作者的文章,难免会把一些多媒体文件或其它供下载的文件链接复制下来,对于抄袭者来说,这可能不会带来什么影响。但对于原创 者来说,影响可能是巨大,甚至是致命的。
就拿可能吧来说,可能吧的空间月流量是20G,假设那篇35个导致你的博客冷清的 理由里有5张图片,每张70K,一共就是350K,而且这些图片都存储在可能吧所在的服务器里,如果这篇文章被纯复制了1000次,平均每篇文章每天被浏 览30次,那么一天由这些图片产生的流量就是10G了,这只是一篇文章而已,一天而已。所有可能吧没有把图片存放到自身的服务器,而是存到相册空间里。如 果真的存放在自身服务器里,那么我的流量可能一天就用完了。
说到盗链,不得不提迅雷和百度MP3搜索,迅雷的候选资源使多少站长痛恨之极啊!这些流量没有带来页面浏览量,是白白地失去了流量,在中国,目前来说流量还是比较贵的,这样失去的是金钱啊!百度MP3搜索也是如此,给人废流量。我相信大多数站长都不会喜欢这两者。
要解决盗链问题,对于转载,引用的情况,可以把多媒体等文件下载到本地再上传到自己的空间里,这是道德的表现,赢得别人对你的尊重。对于抄袭,这就不说了,本身就是不道德的,你不能期望它能做出你喜欢的事。
可以说,转载,引用,抄袭,盗链,正是当今中国互联网的四个极其重要的关键词,不解决这些矛盾,中国互联网不会健康成长。
除非注明,本博客文章均为原创,转载请以链接形式标明本文地址
本文地址:http://www.kenengba.com/post/292.html
Trackback地址:http://www.kenengba.com/post/292.html/trackback
Labels: 中国, 引用, 思考, 抄袭, 盗链, 转载
Sunday, May 17, 2009
解读开源软件七种盈利模式
法律条款都公开 但律师照样赚钱!
医学知识都公开 但医生照样赚钱!
软件行业由于其技术的特殊性,软件存在源代码与二进制代码之分,存在编译过程。导致源代码一直成为盈利的一个新卖点。但任何行业都一样,都存在一个发展和变迁的过程。软件行业也是如此。
如今开源软件已经在全球范围内迅猛发展。开源产品已经完全可以替代现有商业软件。
包括操作系统Linux,浏览器FireFox,开源ERP/CRM信息化方案,服务器应用平台Apache,数据库MySQL/PostgreSQL,开源编程语言PHP/Python/Perl/Ruby,以及各种桌面应用工具。
而作为开源软件的盈利模式也正如法律,医学一样是以服务为主。包括软件项目的订制,软件产品的部署以及后续的检修升级等过程。
而开源行业发展至今始终未出现良好的盈利模式。主要原因有三点:
1、最初涉及开源的都是技术人员,此类人士大多是技术爱好者,对于商业方案不甚了解。况且他们认为做开源就是为了让技术共享,让软件免费。完全的理想主义者。
2、由于二十一世纪初国内媒体对开源的宣传失误,导致业内人士普遍认为开源软件就是免费软件,因而在国内市场很难顺利实现商业化运作。
3、国内开源相关技术人员太少。无法形成本土的开发力。导致众多的商业项目是基于国外项目开源项目打包而成。这严重破坏了开源软件的商业模式。
但同时随着开源软件的不断发展,加之近期业界对开源的不断关注。使开源软件再次回到人们视线当中。不少企业已经开始尝试使用开源软件来进行企业信息化部署。
就技术角度分析,开源软件发展已经非常成熟,各类信息化应用软件和商业公司开发的软件已无差异,甚至性能超过商业软件。这也是开源的优势所在。
其次,政府不断加大开源推进力度。倡导开源操作系统的普及,鼓励基于开源平台的技术应用。这样的局势无疑为市场的开拓打下了坚实的基础。
最后我们分析下开源软件本身所具备的盈利模式以及它与连锁店特许经营模式结合后所产生的联动效应。开源软件在发展历程中,已经不仅仅是开放源代码的免费软件。开源软件与商业并不冲突,它是一种新兴的商业模式。与传统的商业软件相比,开源软件采用了开放源代码、免费分发等形式,减少了营销与销售成本,更易于广泛传播。
开源软件可以是成功的商业行为,那么这意味着什么呢?首先,商业公司必须要能够生存和盈利;其次,商业公司生存的意义在于为用户创造价值。那么我们来看看开源软件是如何生存、如何创造价值、并如何借助其创造的价值来获得回报的。在开源软件领域中,常见的盈利模式一共有7种。下面,让我们来逐一列举和分析。
盈利模式之一:多种产品线
在这种模式中,利用开源软件为能够直接产生收入的专有软件来创造或维持一种市场地位。例如,开放源代码的客户端软件带动了服务器软件的销售,或者借用开源版本带动商业许可版本的产品销售。这种模式应用的比较普遍。如 MySQL 产品就同时推出面向个人和企业的两种版本,即开源版本和商业版本,分别采用不同的授权方式。开源版本完全免费以便更好的推广,而商业版的许可销售和支持服务则可以获得收入。例如 Redhat 自 Redhat Linux 9.0 后将原桌面操作系统转为 Fedora 项目,借 Fedora Core Linux 在开源社区的声望而促进 Redhat Enterprise Linux AS/ES/WS 服务器产品线的销售。
盈利模式之二:技术服务型
在这种模式中,开放源代码软件采用了一种全新的市场定位,并非面向产品,而是针对技术服务。JBoss就是这种模式的典型代表。JBoss 应用服务器完全免费,而通过提供技术文档、培训、二次开发支持等技术服务而获得收入。
盈利模式之三:应用服务托管(ASP)
这种模式适用于基于开源软件的应用服务供应商(ASP)。例如,PHP Live! 就是一种构架于 PHP、MySQL 之上的开源软件,它可为企业用户提供实时交谈服务。目前已经有数十家公开提供 PHP Live! 托管服务的应用服务提供商。
盈利模式之四:软、硬件一体化
这种模式是针对硬件制造商的。随着竞争的普及,市场压力迫使硬件公司开发并维护软件,但是软件本身却并不是利润中心,因而采用开源软件。这种模式为大型公司广泛采纳,比如 IBM 、HP 等服务器供应商巨头,通过捆绑免费的 Linux 操作系统销售硬件服务器。HP公司的Linux系统部总经理、国际开源研发实验室的Martin Fink曾撰写《Linux及开放源代码在商业经济中的应用》,该书详细的阐述了开源所具备的商业模式。SUN 公司已经将其 Solaris 操作系统开放源码,以确保服务器硬件的销售收入,也是这种模式的体现。
盈利模式之五:附属品
在这种模式中,出售开放源代码的附加产品。比如在低端市场,出售杯子和T恤衫等;在高端市场上,出售专业编辑出版的文档和书籍。O'Reilly集团是销售开源软件附加产品公司的典型案例,他出版了很多优秀的开放源代码软件的参考资料。O'Reilly实际上雇用和支持了一些著名的开放源代码黑客(例如 Larry Wall和Brain Behlendorf),并以此提高它在市场上的声望。
盈利模式之六:品牌战略、服务至上
在这种模式中,开源公司通过开源软件先天的传播优势,以极低的成本建立和传播品牌。并通过向用户提供产品相关的服务来获得回报。康比尔公司的 Compiere ERP & CRM 软件是这种模式的典型案例。康比尔公司开发了开源的 ERP & CRM 软件,由于其产品优秀,很快便获得了北美、欧洲和亚洲中小企业用户的认可,Compiere 品牌也因此迅速地传播到了世界各地,在企业管理软件市场已经成为全球知名品牌。
盈利模式之七:市场策略
这种模式,是一种快速抢占市场的营销策略,主要是为以后增强版产品的销售打下基础。 这种情形的案例有很多。比如,微软宣称部分的公开 Office 的源代码,就是执行这种策略。另一个案例则是CRM 领域的新星 SugarCRM,这款由速加科技开发的开源版本从2004年上半年公开下载后广为传播,为在9月推出的盒装专业版套件做好口碑上的准备。
开源软件的经营模式多种多样,随着开源软件的发展,会有更多的盈利模式应运而生。事实上,一家公司可能混合采用其中的几种盈利模式,比如康比尔公司不仅采用了第六种品牌策略,同时也采用了第二种提供技术服务的方式。在开源软件大潮的冲击之下,包括微软在内的商业软件公司,也开始认可开源软件" 软件成为服务 "的本质。微软支持的金牌合作伙伴已经提供包括 Exchange Server 2003、SharePoint Server 2003 等在内的托管服务,如 ASP-One.com 每月每用户起价1美元的 SharePoint Server 2003 租赁服务和全包价9.95美元每月的Exchange Server 2003 租赁服务。
在欧洲和亚太地区各国政府的压力下,微软被迫开放Windows 和Office 的部分源代码,以改善政府的信任度,赢得庞大的政府采购订单。开源软件的商业运动正方兴未艾。这是否会对传统的商业模式构成致命一击?开源软件在走向成熟的过程中,企业用户和政府用户由怀疑上升到愿意尝试,并最终形成了信任。开源软件已经成为软件业未来发展的重要趋势。正如 Navica 公司 CEO 本纳德.高登所说,"短短两三年间,任何人在选择任何企业软件之时,都开始考虑一个问题:是否有开源软件可作替代?",LUPA主席张建华说"开源软件将为解决高校学生就业难的问题提供很大的帮助"。先行一步必将把握商机,开源软件等待大家的到来。
Labels: Open Source, 开源软件
Wednesday, May 06, 2009
强大的僵尸网络:一小时内可竟可窃取5.6万份密码

http://www.cnbeta.com/articles/83479.htm
加州圣巴巴拉大学(UCSB)的计算机病毒科学家们近日就他们对僵尸网络的研究结果发布了一篇研究报告。研究者们发现该网络窃取了容量高达70GB的用户资料,在一个小时之内,这种网络就能获得5.6万份用户密码。这份报告不但揭示了僵尸网络的内部工作机理,也为互联网用户们敲响了警钟。
位 于僵尸网络中的电脑被一种名为Torpig的木马程序控制,它的目的是窃取Windows用户的隐私及财务信息。研究人员利用僵尸网内的染毒机器在定位控 制服务器时的一个漏洞获得了对僵尸网络的控制权。这些染毒机器会生成一系列准备与之联系的控制服务器的网络地址域名表,不过并不是所有的域名都是注册过 的,研究人员抢先注册了域名表上的域名,再用这个地址组建服务器,这样便获得了网络控制权。10天后,僵尸网的原主人才发现并修补了这一漏洞。

研究显示大约有0.1%的染毒网络用户喜欢在网上相互辱骂,而另外4%的用户则成天在网络上寻求性刺激。其它人则表现如常,他们大多为学习,工作和生活担忧,因此在网上找工或寻求帮助。
当然,Torpig的首要目的是窃取用户的财务信息。这些信息包括信用卡号,银行帐号等等。10天之内,Torpig就获得了410家金融机构中的 8310个帐号信息,这些机构包括PayPal, Capital One, E*Trade以及Chase。而约有40%的账户都是被假扮的浏览器登录界面窃取的,这些被窃账户的总额将在8.3万至830万之间。
据报告称,僵尸网络的受害者们通常对电脑疏于维护,而且也总是使用脆弱的密码防护机制。而这恰恰是病毒赖以生存的温床。“即便是受到良好教育的用户,他们可能熟知汽车的保养和安全措施,但却对电脑安全一无所知。”
关于这份报告的详细内容,读者可以点击这个链接进行查看。
CNBeta编译
原文:arstechnica
Labels: 僵尸网络
Sunday, May 03, 2009
如何用mediawiki建一个wikiblog
刚刚用mediawiki(wikipedia所使用的wiki平台)建了一个wikiblog(又叫作bliki)——维基观察,就是一个建立于wiki平台上的blog。所使用的主要的mediawiki扩展如下(这里可以看到我所使用的全部扩展):
WikiSkin:优点是可以完全定制自己wiki网站的版面布局(在这里定制),缺点是原来系统自带的所有CSS样式斗废掉了,全部要自己在Common.css里重写,当然这样会更灵活和方便。在LocalSettings.php里设定:
require_once(”extensions/Wikiskin.php”);
$wgWikiSkinArticle=Wikiskin;
HeaderFooter:定制自己每个页面的头部和脚部,这里头部是页面中条目标题开始处,脚部是条目内容结束处,不是整个页面的头部和脚部。这个扩展非常灵活,甚至可以对每个页面都定义不同的脚部和头部,搭配wikiskin就更加强大灵活。设定:
require_once( “$IP/extensions/HeaderFooter/2.0.1/HeaderFooter.php” );
StubManager:HeaderFooter扩展所需的东西。设定:
require_once( “$IP/extensions/StubManager/1.3.0/StubManager.php” );
ArticleComments:为wikiblog的每篇文章增加blog风格的留言系统。设定:
require_once(’extensions/ArticleComments.php’);
$wgArticleCommentsNSDisplayList = array(NS_MAIN, NS_TALK, NS_USER_TALK); //设定在哪些名字空间显示留言板
$wgArticleCommentDefaults['showurlfield'] = true; //是否显示url填写区域
DynamicPageList2:根据你设定的条件显示内容。我的wikikblog的側边栏和首页等都是用他生成的,这样就不用像平常的wiki那样一页一页手工更新内容了。可能的问题是,过于复杂的DPL会增加服务器的负荷。设定:
require_once(”$IP/extensions/DynamicPageList/DynamicPageList2.php”);
WikiArticleFeeds:blog怎能没有feed?但是mediawiki所提供的几个rss输出的都是wiki化文本,不是浏览器可读的HTML。这个扩展则可以在某个页面生成该页面的rss。但是问题是这个扩展对于中文系统的支持有问题,中文下无法检测出作者和日期。设定:
require_once(’extensions/WikiArticleFeeds.php’);
$wgFeed = false; //禁止掉系统自带的rss
$wgMaxCredits =-1;
各种条件判别等比需有ParserFunctions,这样你的wiki才够强大,才可以作很多事情。如果你要向我一样弄个分类云,则要装ParserFunctions (extended)和Variables:
require_once(”$IP/extensions/ParserFunctions/ParserFunctions.php”);
require_once( “$IP/extensions/Variables/Variables.php” );
blog上还会用上许多Widgets,那就装上它:
require_once(”$IP/extensions/Widgets/Widgets.php”);
$widgetNamespaceIndex = 274;
$wgGroupPermissions['sysop']['editwidgets'] = true;
不要让人随便编辑,那么就装上EditOnlyYourOwnPage。这样其他注册的用户就只能编辑自己的用户页和用户对话页。和ArticleComments搭配非常完美,用户可以通过它在对话页留言。
有了这几个扩展,一个wikiblog就基本建成了。为了增强更多的功能,更像一个blog,可以设置一下:
$wgUseTrackbacks = true; //启用Trackback功能。但是貌似只能提供本站的Trackback,而不能ping别人(我自己顺便测试一下)
$wgNoFollowLinks = false; //对http://这样的连接不使用NoFollow
$wgShowSQLErrors = true; //调试用
$wgHideInterlanguageLinks = true; //把mediawiki上的跨语言连接功能去掉
$wgUseCommaCount = false; //文章计数方式
$wgAllowExternalImages = true; //可以直接引用外部图像
设定网站的logo:
$wgStylePath = “皮肤所在路径”;
$wgLogo = “{$wgStylePath}/common/images/logo.png”;
设定网站的favicon.ico(可以用这个在线制作)
$wgFavicon = “$wgScriptPath/favicon.ico”;
设定好cache,优化访问速度:
$wgUseFileCache = true; /* default: false */
$wgFileCacheDirectory = “$IP/cache”;
如果要使用维基共享资源上的图片,可以这样设定(必须是1.13以上版本才支持):
$wgForeignFileRepos[] = array(
'class' => 'ForeignAPIRepo',
'name' => 'shared',
'apibase' => 'http://commons.wikimedia.org/w/api.php',
'fetchDescription' => true, // Optional
'descriptionCacheExpiry' => 43200, // 12 hours, optional
'apiThumbCacheExpiry' => 43200, // 12 hours, optional, but required for local thumb caching
);
现在基本上看不出太多的wiki痕迹了。但是还有一些问题目前不好解决。一个是评论功能只能一篇文章显示它最近的一条评论,而不能按照顺序列出一篇 文章的多个评论。二是目前的这个wikiblog没有tag功能,貌似wiki天生就看不上tag,我这里就是勉强用分类来代替tag。三是文章的存档还 是必须自己来弄,系统不会自己生成。
另外,用medawiki建立blog并不是只有这一种方法。例如用wiki左右编辑平台,而文章出版平台用wordpress,见WikiToWordPress。或者是用wordpress的评论功能作为wikiblog的留言系统,见WordPress Comments。甚至以用户为单位的blog系统:My blog。(这个适合作多用户的wikiblog,或者叫做WBSP?哈哈 :))如果你有服务器的操作权限,你也可以用wikilog这个扩展建立blog(这个扩展相当不错)。可以参考这个wikiblog。这个是我见过的第一个中文wikiblog。
PDF to Excel:号称最精准的PDF-to-Excel文件转换器

http://www.cnbeta.com/articles/83265.htm
感谢Sheik的投递
新闻来源:Smashing Apps
PDF to Excel,看看这个名字,大概就能猜出它和PDF to Word的关系了。对了,它们同是Nitro PDF Software出品,只不过PDF to Excel出世晚些而已。和它老大一样,它也继承了“the Most Accurate”的头衔 ,最精准的PDF-to-Excel文件转换器。
兄弟就是兄弟,主界面还是那个模子
这是经PDF to Excel转换生成的xls文件截图(pd源文件见此)
事实上,PDF to Excel是将pdf文件中的图表提取出来生成一个单独的xls文件,方便读者查看和使用这些数据。
由于PDF to Excel还是Beta阶段,存在些许问题尚属正常。比方说一张分布在两个页面的表格,经它一转换,就变成两个Table了(一个表会生成一个 Table)。再如某些特殊表格,它就没法识别,会在邮件里提示“No Tables:*.pdf did not contain any tables that could be converted to Excel.”
好在PDF to Excel对中文的支持很不错,尚未发现乱码~
PS:Nitro PDF Software有一个用于html-to-pdf转换的Firefox插件PDF Download,也是很不赖的,大家可以一试~
Labels: PDF
![]()